这章主要讲GPU上的优化技巧
GPU分类
- 固定管线GPU
- Shader GPU
- 通用GPU
根据不同的平台你会遇到不一样的GPU
3D管线
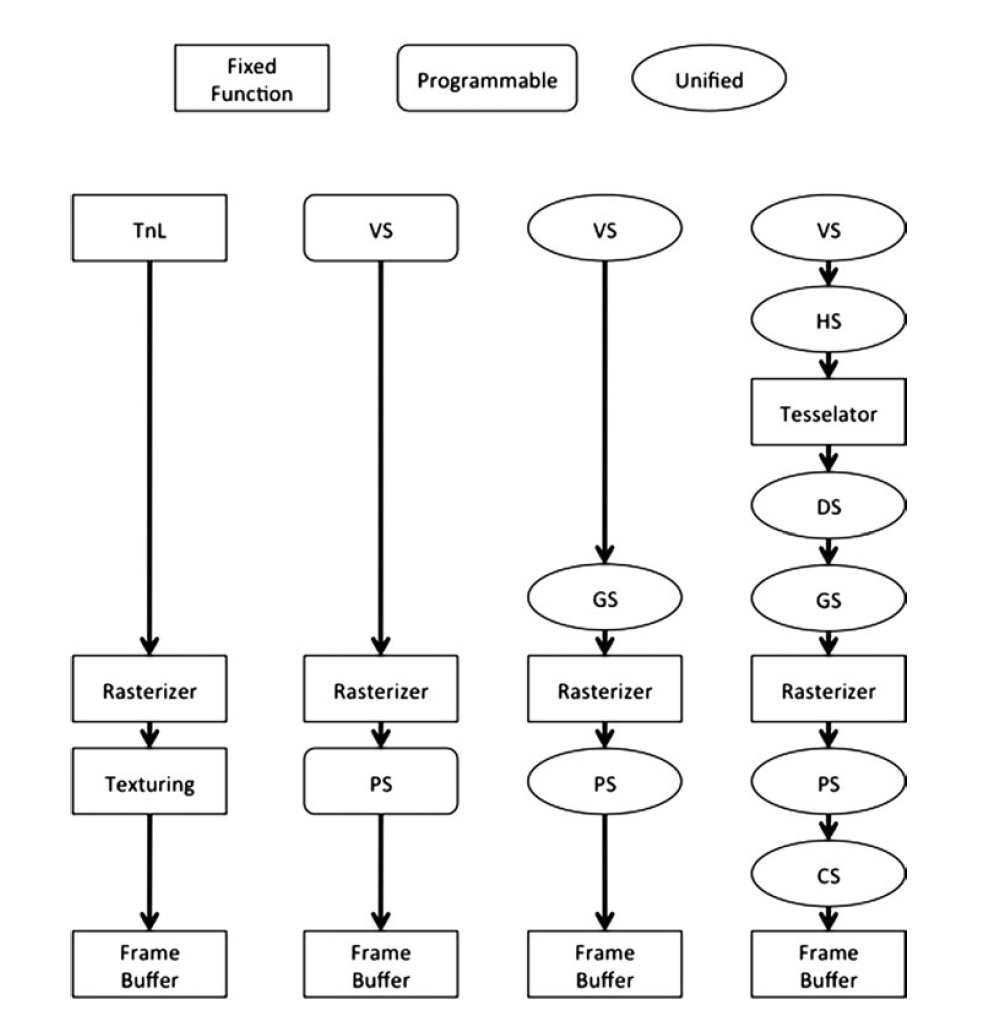
3D管线进步
是否处于GPU Bound
如果你发现API Call特别是Drawcall上面花了很长时间、或者在swap/present framebuffer上面花了很长时间也是如此。这是CPU在等待GPU完成工作。
像PIX、PerfView、GPA这样的工具可以分析GPU的统计数据。如果你发现GPU没有idle CPU有idle那很明显你的GPU Bound了。
如果你知道GPUBound了那下一步就是看时间去了哪里。
一帧长啥样
一帧可以被GPU上一系列的事件填满,每一个事件由API调用决定,数据以某种方式被copy或者处理。GPU维护了一个Command进行执行,所以实际的结果或许需要等前几帧的渲染完成之后才会开始执行。
在PIX的case中你可以通过timeline的方式看到所有执行的过程。
你要做的就是确定那个事件占用了最多的运行资源。
前端 vs 后端
你卡在几何还是像素了,你可以把管线拆成前端和后端来作为优化。前端组装三角形和集合体。后端处理像素执行shader混合结果并且放到framebuffer。
如何测试哪里是瓶颈?
只要缩放rendertarget的尺寸,如果说帧率变化了 那就是后端的问题,否则就是前端的问题。
后端
你会发现后端更容易检测,所以我们先从后端开始:
填充率
GPU fill rate / Frame rate = Overdraw * resolution
Render Target 格式
在PC上支持得最好的是R8G8B8A8。实际上更窄的格式,比如16位,反而会导致性能损失,因为需要额外的工作去写。如果你怀疑瓶颈是framebuffer的格式,改变格式如果性能改变就说明格式是瓶颈。
混合
造成填充率的一个因素是混合。采用alpha混合的时候硬件需要回读已有的值计算最终的混合值。
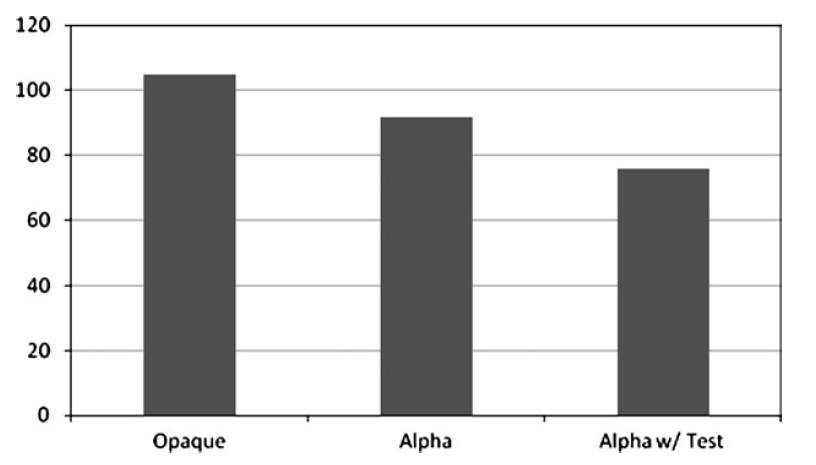
在GTX 260上有以上的测试结果
有很多办法避免这个消耗,例如使用不透明绘制,这是最快的方法。其次就是使用alpha test 如果你需要完全透明或者不透明。
如果两个都不能用你可以近似,顺序无关的透明渲染可以使用。或者使用抖动(ScreenDoor)来保存填充率。
shading
像素shader的消耗非常大,所以有专门的一章去讲。固定管线基本没有这个消耗。如果你在有限制的设备上跑,那需要跑一些快速测试。
贴图采样
贴图采样带来大量的填充率。不同格式的贴图带来的性能影响也不一样。
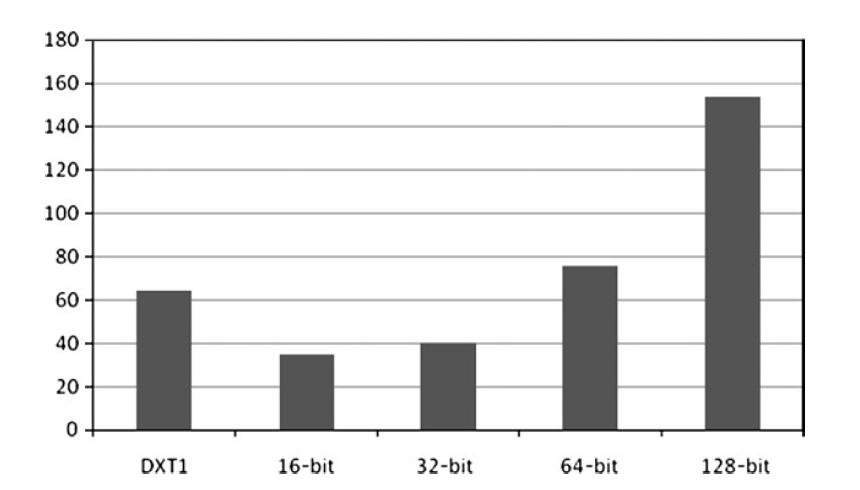
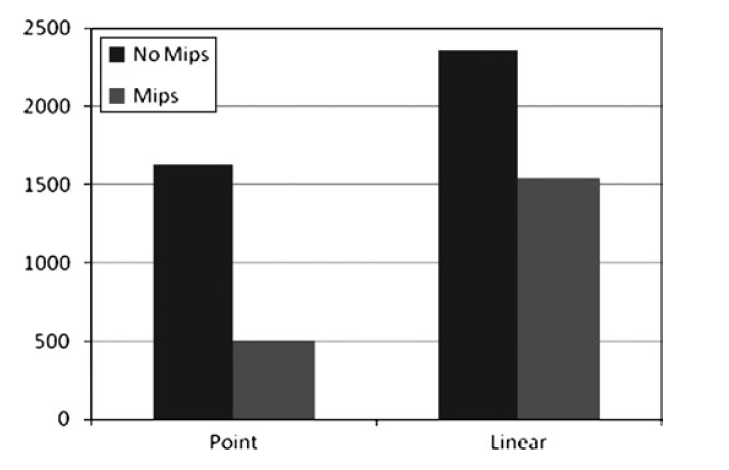
开启Mip和关闭Mip的性能差异。
你可以看到开启mip可以节约大量的性能。
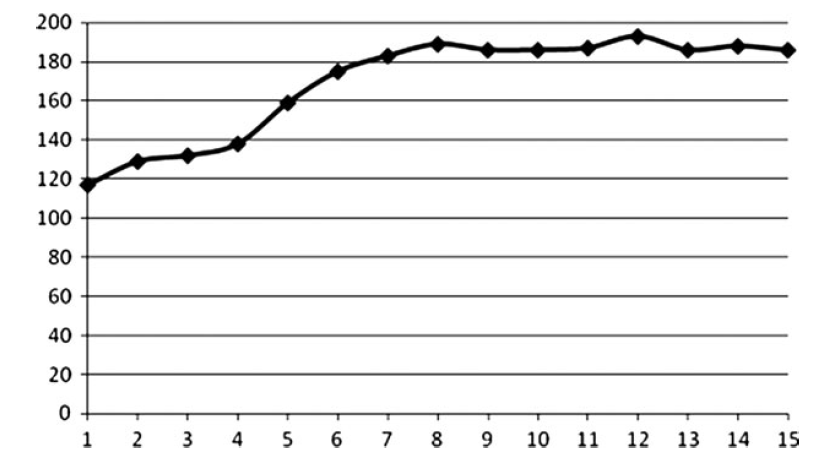
你在shader里面依赖了贴图可能导致性能的下降。
如果你怀疑贴图采样是瓶颈,可以尝试用4×4的贴图或者禁用采样器来查看性能的变化。
Z/Stencil剔除
Z-Buffering是一个主要的提升性能的工具。这很简单,实际上就是先渲染一遍Z buffer,然后关闭Z渲染,渲染一遍颜色,这样可以把所有的无效渲染剔除掉。
但是它存在的问题是需要两倍的Drawcall。如果你Drawcall不是瓶颈,但是渲染是瓶颈的时候可以使用这个优化。
Clearing
清理buffer是很重要的操作。如果Zbuffer和stencil buffer每帧不充值,那渲染就不会正常执行。
虽然clear很快,但是也不要同时调用多次。不然可能会引起bug。
前端
前端主要用于构造几何,然后转换到pixel。基本上在这里性能问题会更少一些,但是已经会出现。如果前端出现问题,那基本上就是三个问题:
- 顶点变换
- 顶点fetching和缓存
- 或者曲面细分
大部分情况都不会是顶点bound,但是还是有时候会发生。
你永远不应该把三角密度高于像素密度。通常通过LOD能够很好地降低面数。
顶点变换
你可以很简单的测试顶点变化的开销:移除顶点变换操作,比如移除光照计算、替换贴图UV为更简单的方式,或者禁用蒙皮,如果性能上涨,那就是瓶颈。
在固定管线的显卡,你需要禁用相关的feature来确认。
顶点fetching和缓存
Index数据按顺序处理,Vertex数据基于Indices。经过index的顶点数据很容易pre-fetch,但是受限于有限的缓存空间,一旦缓存满了prefetching不能隐藏延迟。
几何以图元的形式提交到GPU。最基本的类型是三角list和三角strips。strips有更小的footprint,但是有更大的问题是有多少cache miss在三角片fetch的时候发生了。最大化顶点使用是很重要的。大部分的渲染库都包含了顶点顺序优化的代码。D3DX中有一个D3DXOptimizeVertices的函数,以及Linear-speed Vertex CacheOptimazation的优化。
https://tomforsyth1000.github.io/papers/fast_vert_cache_opt.html
Linear-Speed Vertex Cache Optimisation
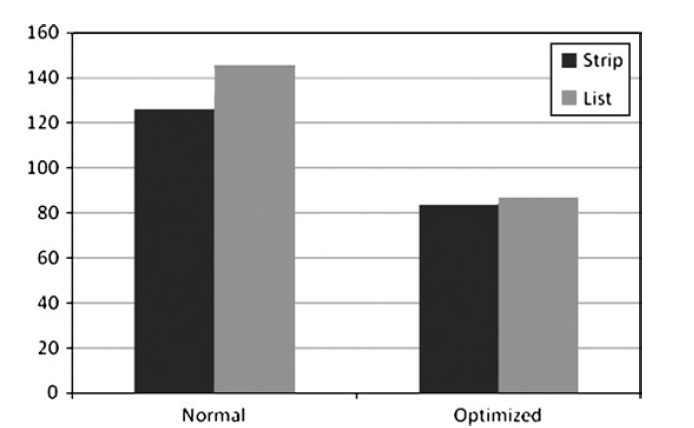
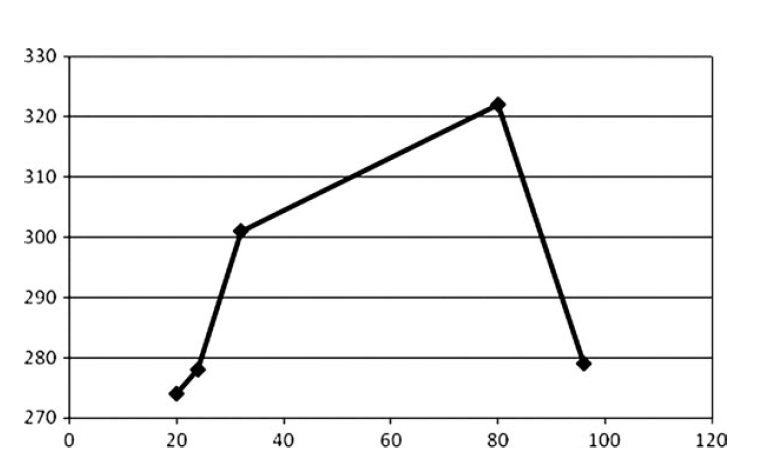
这一部分的优化主要考虑两种情况,首先是index的格式现在有16bits和32bits的indices,下图进行比较:
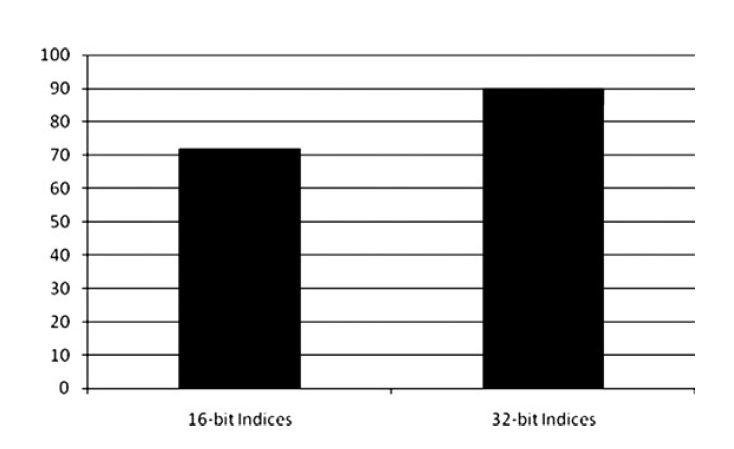
另一个考量是顶点的格式,特别是顶点的尺寸。通过降低整个数据集来获取一些性能,下面是对顶点尺寸性能的比较:
曲面细分
最后一个瓶颈是曲面细分,大部分近期支持DX11曲面细分的都可以改变、删除、发射新的几何体,通过几何shader。我们会在下一章提及。
许多老的GPU对细分的能力都不同,除非你用特定显卡,否则一般是不够灵活或者足够来保证你所花时间在特殊的效果或者一次性代码上。
(现在其实用的好像也不多
特殊情况
下面会讲一些特殊例子
MSAA
MSAA是反走样技术。随着新技术引进,性能也得到提升,但是确实会提高填充率,需要引起注意。
灯光与阴影
灯光和阴影可能是除了简单场景外主要的性能问题。一般没办法简单的解决。灯光需要大量数据来保证渲染正确,而阴影可以影响整个渲染管线的压力,因为需要从不同的视角多次绘制场景。
灯光和阴影主题太大了,这边肯定讲不完,就讲一些指导意见吧。
灯光质量主要关系到精度。好的美术可以通过伪装来最大程度减少灯光甚至没有灯光。人类有着对灯光的知觉。但是灯光质量并不会影响到玩法,所以这个是一个trade-off。
总的来说连续性是灯光最重要的属性,不应该有明显的中断或者缝隙。人类的眼睛很容易就看出下次。人们一般也会很快接受简单的光照计算,只要没有令人不快的瑕疵。
通过一些巧妙的设计来避免性能问题的发生。拒绝可以处理所有情况的灯光的诱惑,决定你游戏的解决方案并且保证在你的游戏中可以正常运行,忽略其他别的东西。
最后灯光计算是屏幕每个像素在计算的,他们必须是线性的。他们或许基于贴图或者多个pass,但是灯光和阴影是和所有的材质交互之后获得的屏幕上所有的颜色。
这里带来的性能问题是,灯光可能要去你把场景和drawcall分开。如果你使用固定管线的灯光,每个物体需要不同的灯光属性。对于小的物体一组数据可以照亮,而大的物体比如地表或者城堡,不同的部分可能照亮得会不一样。
所以给每个物体都照亮灯光是不可取的。所以大部分引擎都只查找N个最近的灯光。
通过这种方法,只有四个灯光可以参与材质计算。对于大的物体,可以让场景计算放在第二个pass。
只要把受影响的物体传到GPU即可了,更复杂的mesh可能不能这么做,而是拆成小块,无需每个三角面片重绘。
灯光是重要的阴影则是灯光和物体的交互。他们带来更真实的场景。阴影一般通过渲染场景深度,然后通过纹理采样来实现。这个提高了填充率当然这也相当于渲染了两次、甚至三四次场景。
好的事情是,他们不需要整个场景渲染,后处理不需要,颜色也不需要只是深度而已。大部分的排序开销,也是可以避免的。
最后灯光系统可以基于我们在这章提到的图元来构建。灯光和阴影的高效实现有太多可以将。但是一旦你知道如何将他们放入你的游戏,这将成为适应你游戏性能的问题。优化过程一直是一样的,找一个benchmark、测量、检测、解决、检查再重复。
前向管线和延迟渲染
最大的游戏改变者,包括性能在内,是延迟渲染。传统的向前渲染是把物体一个个处理到framebuffer里面去。你在所有的render call结束的时候进行快照基本就是一个最终的图了。
在延迟渲染中,发现、材质类型、id、灯光信息以及其他参数都被写入到了一个或者更多的render target里面。在末尾的时候转慢数据的buffer最后处理成最终的图片。这极大简化了渲染。因为即使场景有再多的灯光和shadow也可以用同一种方法处理。将前向渲染的主要问题,灯光数量和阴影用常量的计算来处理。
但是创建延迟渲染的数据并不廉价,需要很大的带宽以及多个RT。大量的填充率消耗非常耗。但是延迟渲染是固定的性能,虽然性能本身较差,但是不会因为场景复杂度提升而变得更糟糕。
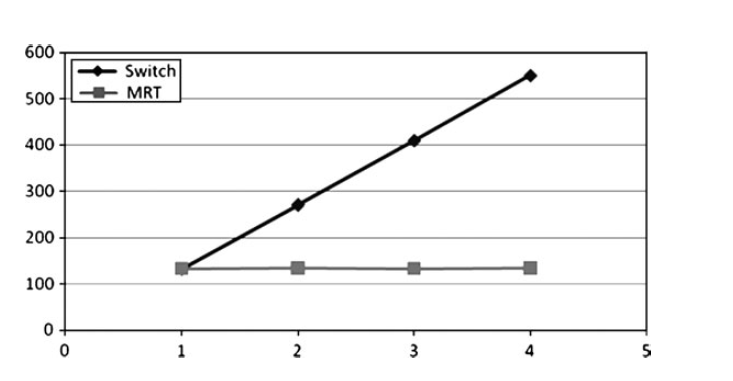
MRT
我们讨论了渲染宽泛的render target,当然也可以同时渲染多个RT。这个称谓MRT。用于延迟渲染、阴影计算或者是优化当前的渲染算法,但是还是会带来消耗。
MRT大部分硬件都支持。