

什么是GPGPU
GPGPU是GPU逻辑进化的结果。过去的几十年每一代的GPU的功能都变得越来越强大。高端GPU有更多的并发单元,因此有更强大的计算能力。在最新的Shader Model中通用计算可以表现得非常好。
一开始研究者发觉他们可以用GPU来分担一些CPU的计算。比如特定的金融和科学运算需要巨大的矩阵。通过在巨大的贴图中存放矩阵数据,并且每像素计算,工作可以非常并行化,来达到主要的速度提升。
这就导致了GPGPU的出现,因为GPU能够进行通用计算。在这个潮流下,开发者逐渐从设计用于渲染图片的GPU转向编写产生精确数据结果的库。在高效的同时,任何东西都可以计算并且可靠地执行。一旦上手之后,性能可以比传统的CPU计算要高三个数量级。
GPU开发者专注于GPGPU作为提升销量的方法,特别对于科学计算和金荣这种高利润的市场。一部分GPU可以作为桌面超级电脑能够支持需要计算中心才有的算力。在消费者市场,中间件包开始提供GPU加速处理。N卡和A卡提供了方便的语言和接口来在GPU进行计算。
与此同时,IBM使用Cell处理器,使用在PS3上。虽然不是GPGPU但是提供了很多相同的概念来提供类似的功能。主要的劣势是缺乏比较好的工具和语言来针对Cell的硬件。
紧随其后的,AMD收购ATI,Inter开发Larrabee,NVIDIA放出了ARM system-on-a-chip集中了GPU和CPU的科技。这个时候不依赖开发商的API也由苹果和微软提出了。允许用户使用相同的代码在不同供应商的GPU上运行。
在编写本文为止进展就到这里但是融合还远远没有借书。我们可以预见到GPGPU将会被大量用户使用并且在更多的应用中被启用,API、语言和工具也会更加成熟。
目前只有少量主要的语言用于GPGPU。大部分是C++衍生出来的:CUDA、Sh、OpenCL、DirectCompute以及Brook,都在这一范围内。他们都很像shader语言。
什么时候适合在GPU中进行处理
目前还没有特别多的PC游戏使用GPGPU,除了物理API。
但是GPU的算力可以用在更多的地方。
如果CPU高负载而GPU没有,那么可以把东西挪到GPU处理。但是把光栅化挪到CPU则没什么意义,因为CPU没有这么高效进行光栅化。类似的,如果你的任务是GPU友好的,并且是高计算的,则需要注意可以尝试挪过去。换句话说,当算法和GPU处理的设计映射到位,移植到GPU可以得到翻倍或者是三倍的性能增长。
你应该考虑使用CPU而不是GPU,如果你的算法有大量的分支,在并行在大量线程上的时候有很多不一样的条件。虽然GPU支持分支,但是并不擅长处理分支。在一些情况下GPU编译器可以通过trick来降低性能下降。或者你在多个线程中将类似分支的逻辑进行合批。在缺乏这些trick的情况下优先使用CPU。
如果你期望一个计算并且阻塞到它结束,那么GPU是并不是一个好的处理器。传输到GPU的过程非常漫长,除非你使用了是固定特定组织的机器,例如XBox360,你不会想在一般情况下被CPU与GPU之间的传输导致性能下降。更好的方法是把计算合批然后一起在GPU进行处理,最后把数据打包返回。这降低了每个计算的overhead。
最后GPGPU将会在shader model4成为最低支持的时候大量应用。如果你没有使用model4的硬件,你可以需要同时编写CPU和GPU的两种版本,并且基于你的硬件参数来选择正确的版本。虽然有在Shader Model2中实现的动画和蒙皮,但是并不是完全通用的做法。当有更多的硬件支持之后,我们才能更容易地支持GPGPU的解决方案。
GPU上跑图形以外的东西有多快
所以GPU真的能够处理GPU厂商宣传的这些东西吗。如果不行的话也不会写这一章。Kronos group和NVIDIA和微软也不会花大力气去做API。
看一下banckmark。
(列举若干现实数据
一般来说如果是GPU友好的算法基本会有10~100倍的提升。
GPU系统执行过程
GPU的图形处理管线也许被作物命名了。回头来看,发起这项技术用于游戏也许是个策略而不是战略——也许游戏只是达到目的的手段?GPU是半导体并且虽然他们的结构帮助定义了你的光栅化关系,在他们的核心他们是关注处理器硬件提供数据并行处理并行数据流的。
我们解释一下之前GPGPU处理交流的过程。如下图:
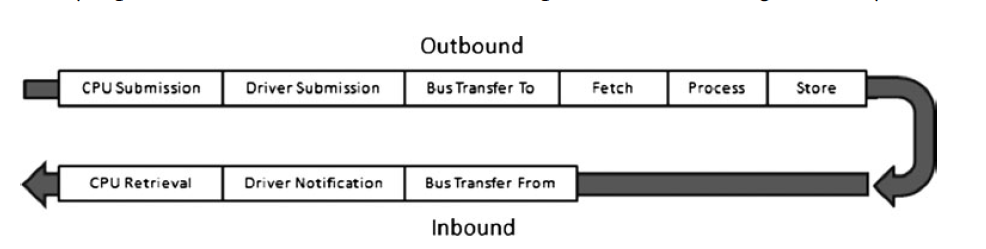
通过这么长的一个传输过程,GPU如何做到光栅化比CPU更快?
答案是吞吐量。即使GPU有延迟,单看一个操作的传输是非常糟糕的,但是吞吐量确实非常厉害的。GPU通过这种设计方法来做到CPU无法做到的高效。
GPU花了大量的工作来保证处理阶段,是并行并且连贯的。这是实现吞吐量的基本条件。这个操作也是高度并行的,增加了处理率以及连贯,增加了内存读写的效率。与此同时,大量处理同样的指令,数据是arranged、fetched并且尽可能地线性处理的。并行和连续是今天许多处理器的目标。GPU的实现是在计算硬件远大于内存和指令fetch硬件的。通过使用GPU的方法你作为程序员,放弃灵活性,除非算法本身就非常符合这个架构。我们会在这章中大量提到并行和连续。
会狂吞吐量。通过立交并行和连续的重要性,我们可以更进一步看一下内核的行为。一个内核在基础的定义是一组指令的小程序。GPGPU的内核是和图形API的shader类似的。使用简单的伪代码我们来测试多高的延迟依旧可以保持高吞吐。
pChassis = GetChassis();//5 min
pFrame = BuildFrame( pChassis );//20 min
pBody = BuildBody( pFrame );//30 min
pEffects = AddEffects( pBody );//20 min
pFinishedCar = FinishedCar( pEffects );//10 min
如果你测量多久可以造一辆车,你可以非常简单地通过加上所有时间。在这个例子里面就是85分钟。如果你想造两辆车需要170分钟吗。假设没有任何的并行,每辆车都需要等前一辆车造完。
一个更并行的设计可以做一条流水线。如果你可以设计可以开始另一辆车在前一辆车结束之前,你可以有更好的吞吐量。如果你从时间0开始造车。在85分钟可以完成。如果你尽可能快地造第二辆车,它会在1:10分钟完成。如果你测量每小时造车的时间第一辆车会1/(85/60)也就是0.71.如果你测量两辆车会变成2/(115/60)也就是1.04辆车每小时。你增加了三分之一的效率。如果你加了第三辆车则变成1.44.在这个例子,你会发现越来越接近三辆车每小时的效率。瓶颈在延迟到达120分钟的时候发生。下表可见:
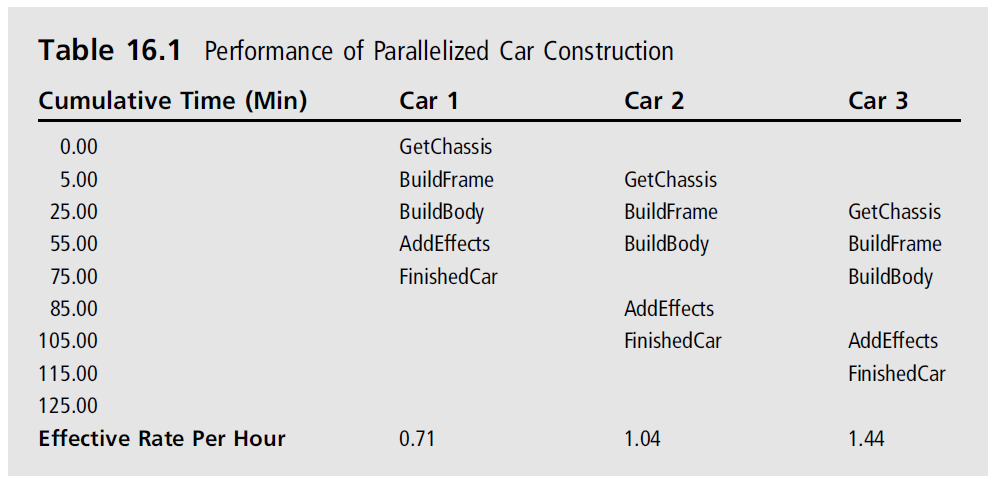
这种类型的性能增长印出一种可能。流水线需要尽可能填满。开始和停止流水线会导致严重的性能下降。差异在0.71到3之间。另外一个假设是系统能够支持完全快速地提供原材料来保证流水线不会阻塞。这就是为什么数据并行如此重要。
一个并行的特性是扩容不需要任何开发者的代入。假设系统可能提供数据足够快,你可以直接复制整条流水线使用相同的实现。这就是GPU所做的。这种并行称作SIMT,或者单指令多线程。
架构
理解GPGPU的性能需要了解底层的硬件。还好这和之前使用过GPU的人来说没啥区别。我们快速看一下架构然后看一下主要的性能特性。我们通过CUDA来看一下GPGPU的技术。
统一核心和内核
DX10的卡带来了追加的功能和更高效的硬件使用率。之前的版本顶点处理和像素处理发生在不同的硬件上。在DX10上他们的计算单元被任务平等地进行分配。
这是GPGPU处理的基础。在硬件的另外部分,例如顶点装配,光栅化操作单元,帧缓冲硬件是在大部分GPGPU应用之外的。了解核心以及设计你的算法来适应架构是榨干吞吐量的关键。
然后我们讨论一下执行模型,如何运行时和驱动在可用的处理器中分配。
执行:从底往上
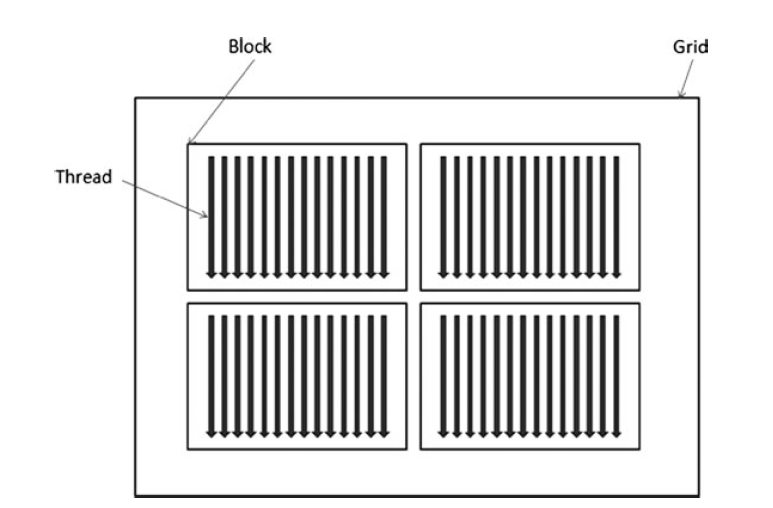
GPU用于解决尴尬的并行问题,所以他们针对并行从下往上设计。对于我们的需求,我们会从线程开始往上提高。一个GPU线程不同于CPU的线程用于开始和结束很频繁。另一个很大的不同是有远远更多的GPU线程同时在运行。而且又更多的硬件绑定在每个线程上。一个算法可能利用上百个GPU核心。最后一组线程执行相同的代码,而CPU线程则是每个都有自己的代码。下图可以看出block、grid和线程的关系
Wrap
对于执行目的,SIMT单元把一组执行的线程成为Wrap。在CUDA中Wrap是32个线程,但你可以通过API查看最大的硬件支持的Wrap尺寸。Wrap执行相同的并行指令。
GPU支持分支执行wrap。控制流指令导致wrap串行,执行相同值的分支,而禁止另外的执行分支。在这些情况下,性能成为了功能性的牺牲。幸运的是性能只会影响分支的分期不分。你可以通过将大部分的分支走相同的条件来缓解性能的下降。
Block
GPU的Thread通过Wrap执行,一个更大的容器称作block,定义了更高层级相同功能的容器。block会执行在一个处理器核心,作为开发者你会知道执行block里面的内容会使用本地资源,不需要支持跨核心问题。开发算法的时候作为独立block,保证你的算法是可伸缩的。block执行可以发生在一个或者两个三个维度,也许可以帮助开发者将算法映射到对应的执行模型。
Block有本地内存,帮助block分享内存。你可以保证一个本地内存的获取。分享内存是低延迟的。所以利用这个特性可以大大提高block的执行效率。内存的生命周期和block的生命周期相同,所以当所有的wrap执行结束,block里面的内存也就不复存在。
线程同步在block域中也是允许的。在CUDA中如果一个内核需要同步数据,可以使用syncThreads()。SIMT单元会调度wrap并且执行block知道每一个线程到达同步栅栏。一旦所有的线程到达,调度器会结束block的执行然后继续。
当host(CPU或者客户端)执行内核,CUDA列举blocks然后分发到不同的GPU处理器上。当考虑block层,开发者应该知道block不需要处理依赖。block应该以任何顺序执行而不会影响算法。
Grid
Grid是Block的机核,而由开发者指定大小。一个grid的尺寸是一个是可以接受的。但是内存也许要去额外的grid来提供另外层级的细分。
内核
一个内核启动了一个函数并且制定了一个grid大小,block数量以及线程数量。内核操作是线性的,也就是如果应用程序按顺序调用内核,他们会按顺序执行。
一个例子会让东西清晰。我们来看CUDA。为了调用CUDA的内核,我们并行先编写内核然后调用它。调用内核和调用函数很像,只不过使用了<<<>>>操作符,定义了grid的数量以及block的维度。
_ _ global _ _ void MatrixMultiply( float A[N][N],
float B[N][N],
float C[N][N] )
{
int i= threadIdx.x;
int j= threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
int numGrid = 1;
Dim3 dimBlock( 4, 4, 1);
MatrixMultiply<<<numGrid, dimBlock>>>( A, B, C );
}
在这个例子里面,函数MatrixMultiply执行了十六次所有的执行,在一个多处理器的一个wrap中。ABC这三个矩阵储存在全局内存,不是最好的情况。为了最大化性能,举证应该放在正确的内存结构里面。
瓶颈
GPGPU里面可能会出现几个性能问题。在下面的几个环节我们会运行他们并且讨论解决方案。优化概念在6、7、10章中都有提高。
和主机交流
类似于图形编程一个主要的性能瓶颈倾向于获取GPU外的数据和指令。这可能比任何的计算工作要更耗时,你要保证工作是足够大的来同时执行。
当数据量很少的时候大部分的时间永远拷贝和传输,随着数据量的增大性能会快速上升。
内存和计算
GPGPU暴露了更多复杂的内存层级结构比传统的GPU程序更加复杂。这为目前有多少线程正在运行提供了更明确的信息,为性能调试打开了大门。如果你可以保持你的运算的内存在快速内存中,你会得到大幅的性能提升。相反的经常获取缓慢的数据会造成巨大的性能下降。即使现在大部分的GPU擅长通过调度隐藏延迟。
如果你使用本地数据,你有大量的计算能力来负载你的问题。最大的GPGPU问题是如果高校处理你的数据。一旦这些问题解决你的东西就会快速又正确地完成。
大部分的CPU、内存、GPU的章节的考虑都可以用在GPGPU上。查看数据依赖以及缓存访问友好性。优化内存带宽用量。
在这之上,使用一个好的benchmark以及一些小心的测量。确定你的瓶颈并且解决它,然后检查你的改进,重复以上步骤直到你获得可接受的性能。