

利用多线程可以用更少的时间处理相同的工作。如果是真的为啥不是每个人都实现多线程算法?更多的疑惑是实现了多线程算法之后为啥还是单线程运行更快。
回答是创建线程简单,创建多线程很容易,但是从多线程应用中获得优化很困难。最大的风险是并行代码串行化,这是另一个需要解决的问题。
首先我们要看为啥多核CPU如此受欢迎并且多线程背后的基础物理问题使它如此强大和难以使用。我们列举一下线程与性能相关的属于。最后我们会给一些粒子用于调试并行代码。这个章节不让你成为专家但是让你的多线程代码运行得更好。
为何多核
为啥使用多核?单核不是越跑越快吗?这涉及到微处理器的物理限制。
单核处理器最终的性能限制在哪里?一个限制是光速。现在没有人怀疑光速是最快的。这成为了主要问题。芯片越来越大,芯片信号花费的时间成为了最大的问题。
我们希望所有东西都越做越小来最大化速度,但是尺寸也是有限制的。光刻需要通过光源来打印芯片,而光的波长决定了每一块芯片的最小尺寸。电子发射无法比光速更快,随着芯片大小增加,光速的限制也就越来越明显。
科技发展中,有另外两个方面可以增加性能通过增加频率。一个是功耗吗我们增加频率我们也增加了功耗。不幸的是,功耗不是线性的。我们使用了大量的能源但是能源必须有地方去,芯片的损耗会非常快。
额外的是,芯片需要剩下的系统一起跟上。内存的延迟限制,其他系统的部分一样。另外的问题是我们从内存获取数据的问题,CPU变得更快,但是内存访问速度却止步不前。
当构建城市的时候我们不可能只把一座塔造的巨高。每个建筑有不同的高度,构筑用于自己的用处。多核远比单核要更容易。通过增加更多的核然后降低频率,这样不需要使用更多的电量,我们也可以获得更高的性能。
对于笔记本来说是个好消息。
当然进化不会停止。晶体管持续降低尺寸并且增加速度和效率。频率增加功耗降低。基础性能也会持续上升。
载我们进入多线程开发前,我们可以感谢硬件、编译器以及操作系统开发者做了大量恶心的工作。指令层并行给了我们有限的并行,降低了多线程给系统的压力,并且不需要应用开发人员额外的工作。
但是大部分情况下最好的情况是应用程序主动使用多线程。单处理器多线程或者单处理器单线程都可以。
为何多线程是困难的
线程是最小执行单元。线程的创建依赖你使用的API,有上层API类似于OpenMP或者Intel的TBB。底层API类似于Windows和POSIX的API。
线程有两种类型:启发式和协作式。协作式很简单,当线程准备好的时候就转移到另一个线程。但是问题是每个线程运行都是公平的,如果一个线程挂了整个系统都宕机了。
现代操作系统实现的是启发线程。有一个调度管理器,基于若干规则,负责切换线程,这样就可以正常工作。切换的工作称为上下文切换,涉及到拷贝整个线程状态。包括寄存器、栈和系统上下文,决定下一个线程的状态。
上下文切换可能发生在任何时候,可能直接就在代码之间。
不可预测的上下文切换让我们的bug变得不可预测。很容易就出现难以复现的问题。
多线程编程需要知道同步模型:mutexes、信号量、条件变量等等。但是使用同步逻辑常常导致性能问题。
最小化同步并且保证逻辑正确是一门艺术。
数据和任务并行
把任务拆成多分可以方便任务同时进行,这个操作一般称作分解decomposition。一般有两个部分:数据并行和任务并行。
数据并行你可以通过数据拆分之后然后对每一块进行处理。
数据并行包含分离和合并两个阶段。
为了理解任务并行,就像把一组任务拆分成类似于流水线。没有依赖的任务可以更加并行化。
分解工作得很好,但是在实际中有更复杂的算法混合。现在图形管线就是一个很好的数据和任务并行的例子。
性能
在使用多线程之后没发现明显的性能提升有很多原因,最大的三个原因是:
可伸缩性,线程竞争和平衡
可伸缩性
你会发现增加线程或者核并没有线性的性能增长。很多多线程算法不会显示持续的性能增长,随着线程和核心数的增加。开发可以无限增长性能的算法十分困难。
很长时间里我们使用Amdahl法则来描述典型的伸缩性问题。最大的提速被限制在提升性能那部分所占的耗时比。
$1/(1-P + P/S)$
P是优化的那部分。S是优化的比例。最终可以优化的比例就是结果。
在并行中,我们无法优化的就是线性的部分。也就是我们始终无法优化那部分同步的内容。
1988年Gustafson推出了自己的定则,提供了另一种计算伸缩性的方式:
$S=a(n)+p*(1-a(n))$
a(n)是串行函数。p是核心数。
如果并行算法的工作数越来越大,我们并行的也可以越来越大,而串行则不会随着增长而线性变化。
这两个公式一直被使用,哪个更准确也有争议,但是没有争议的是串行会导致性能下降。尝试移除你算法中的串行部分。
竞争
在完美的情况下我们能够编写完全并行的程序。但是在实际使用中有很多情况下会出现竞争的状态,在多个线程都尝试访问同一个资源的情况下。
有很多方式处理这个问题,他们的复杂性、性能、效率都有很大不同。
最简单的方式是使用停止标记。先到先得原则。你可以通过mutex来实现。你可以快速通过这种方式实现线程安全的系统,例如内存管理器经常使用一个全局mutex。
另一个是把交叉的部分分开。比如我们给每个线程一个单独的heap,而不是存在全局heap中。不过有些情况下这种方式不可行,例如每个线程使用的内存太多,不可能单独给线程开这么多内存。或者共享资源需要内容一致。
即使资源是共享的,也不需要真的在所有时间都同步。比如绘制队列只需要成为双buffer,降低潜在的竞争从一百次降低到一次。
第三个选项是寻找更高效的同步。有时候你可以把单个资源拆成若干个可以单独访问的资源。更细粒度的同步。另外你可以使用硬件支持来让同步操作更快。
同步组件是保证正确性的基本。但每一个都有将你的线程变成线性速度的可能,损失所有你在并行中获得的性能优势。串行是主要的限制多线程性能的限制。
平衡
平衡工作负载是最后的线程性能中要注意的点。就像电脑中需要平衡工作负载来获得最大效能一样。你的多个计算任务需要平衡。多核程序吃满一个核,闲置其他核是很糟糕的。
我们已经有一些强大的工具来profile。根据你的目标系统来观测CPU利用率,如果不太平均就看看如何防止不平均地使用。比如饥饿(没有足够的工作来喂饱线程,或者人为限制)或者串行化(依赖的工作导致无法正确并行)。
后面章节有更多关于保持工作负载平衡的内容。
线程创建
当我们创建线程,我们也创建了线程需求的结构体。这些结构体包含了本地储存,核心栈,用户栈以及环境block。创建线程会有一些overhead以及额外的内存。动态申请小内存可能导致内存碎片化。为了高效使用内存,你应该使用内存池而不是频繁创建销毁线程。
所以一般创建多少个内存,一般是每个核使用一个。但是Windows任务管理器有500到1200个线程,由正在运行的处理器数量决定。虽然Intel建议我们用成百上千的线程,但是我们现在在CPU上并不这么做。
1比1的线程核心比例是一个好的规则,但是就像很多规则,主要的原因还是因为比较简单而不是准确性。所以1比1不是必要的,如果我们用低优先级或者不是性能敏感的,那就不需要1比1的比例。在操作系统经常阻塞的线程也可以有更高的密度。
1比1也是因为硬件支持并行处理。例如,思考六线程在四核心的机器上。因为硬件只支持四个线程,只有四个线程可以同时进行。另外两条则需要等待核心发起调用。
线程上下文切换是另一个大量线程带来的overhead。从一个线程切换到另一个线程需要消耗大量的指令周期。在很多情况下一个线程完成一组工作然后获取下一个工作进行执行比中间中断要更廉价。
线程销毁
你不应该在运行时创建,也不应该在运行时销毁。没有实际的性能和线程销毁的关联。但是必须保证在应用程序关闭之前需要停止所有的线程。如果主线程没有关闭所有子线程,进程会一直存在。
线程管理
通过同步基础设施,你可以有效控制系统去做你想做的事情。
信号量
多年前Dijkstra发明了信号量,拥有两个动作:请求和释放。操作系统通过不同方式实现了信号量,但是所有信号量都共享了最基本的信号量的概念。(mutex可以看做二元的信号量)
class Semaphore
{
// member functions
unsigned int m_Current;
unsigned int m_Count;
//member functions
Acquire();
Release();
Init( int count );
};
信号量是线程请求的守门员。
比如加油站的休息室,有10间,有10个钥匙,前10个到的可以直接那钥匙进入休息室,后面的人需要等前面的人出来之后才能拿到钥匙,进入休息室。
m_Current是当前使用房间的总人数。m_Count是房间的个数。Acquire是拿到钥匙,Release是归还钥匙。
这是线程最基本的操作。不同的操作系统实现不同,但是底层的概念也是一样的,方便理解每个操作系统的实现。
Win32同步
很多游戏都使用了Win32的线程基础,我们会花一些时间讨论。
Critical Section和Mutex
Critical Section和Mutex有类似的功能而有不同的实现和性能影响。Critical Section是用户域匿名的mutex,Win32的mutex则是一个进程间命名的mutex。可以在代码段的前后放置进入和离开的调用,来保护进程或线程的访问数量。
当一个线程进入Critical Section或者使用一个Mutex,另一个线程要进入的时候必须等待前面的线程完成。导致了竞争状态,会引起性能问题。
在Windows中,Critical Section和Mutex之间的区别是哪个层级的可见性。Critical Section只在应用内可见,而Mutex则可以跨应用。Mutex也会平均慢于Critical Section,因为需要处理更复杂的情况。所以一般Critical Section会用得更多一点。
Critical Section和Mutex在Windows下使用类似的接口。Critical Section使用Enter和Leave的语法,一次只能进入一个处理器。Mutex会使用一个等待函数来进入保护代码,然后用ReleaseMutex来退出保护。
Critical Section和Mutex是强大而易用的。不幸的是他们也容易滥用。对于性能考虑,开发者不应该将这两者用于解决多线程问题。因为竞争过于昂贵,非竞争则不是。开发者应该设计算法来降低竞争。如果你用这种方式设计,你可以使用Critical Section或者Mutex作为失败的fallback。降低竞争是最重要的。
信号量
Windows有一个传统的信号量实现。一个windows信号量使用ReleaseSemaphone来增加信号量,WaitForObject来减少。
事件
事件是Windows的二元信号量。所以不是增加或减少事件,而是只有两个状态。有信号和无信号。标志信号可以使用SetEvent()
WaitFor*Object 调用
WaitForSingleObject,提供单个对象的句柄,WaitForMultipleObject提供一些列句柄,你可以用于阻塞一些东西。比如你可以调用WaitForSingleObject在事件句柄上来创建一个系统阻塞来让线程高调等待另一个线程触发事件。等待函数也可以有一个超时参数。超时也可以设置成无限。函数可以等待信号量、mutex或者事件,你也可以设置一个毫秒数来指定最终放弃的等待时间。
HANDLE mutex = CreateMutex( NULL, FALSE, NULL );
DWORD dwWaitResult = WaitForSingleObject( mutex , INFINITE );
If( dwWaitResult )
{
//critical code
ReleaseMutex( mutex );
}
多线程问题
为什么我们做这么多同步操作,如果我们啥也不管会怎么样?这些在竞态条件、伪共享和死锁中可以看到。
竞态
在普通的Race中第一个到达终点的人是赢家,在竞态中赢家可能是最后拿到地址的线程。
竞态创建了不正确的数据,因为不可预知的线程组合行为。最经典的例子就是增加同一个值。正确的方式是:
- 线程A从寄存器读取内存
- 线程A增加寄存器数字
- 线程A写回寄存器
- 线程B从寄存器读取内存
- 线程B增加寄存器数字
- 线程B写回寄存器
而多线程情况下可能导致乱序
- 线程A从寄存器读取内存
- 线程B从寄存器读取内存
- 线程A增加寄存器数字
- 线程B增加寄存器数字
- 线程A写回寄存器
- 线程B写回寄存器
最终导致只写了一次。
伪共享
竞态导致了不正确的执行顺序从而导致不正确的结果。伪共享则是多个核同时使用同一个内存地址。这一般在单核上没办法出现。
在之前的章节你应该理解内存利用了寄存器、缓存和DRAM。因为缓存的存在,部分内存导致了不同步。比如一个核读取了一些内存到缓存中,刚好在另一个核写入同样的内存时,第一个核的缓存上就会存在部分旧数据。当两个或多个核共享一个cache line,内存子系统会强制串行更新数据。这个串行的操作也就是共享导致了overhead,做了原本程序不需要做的事情。
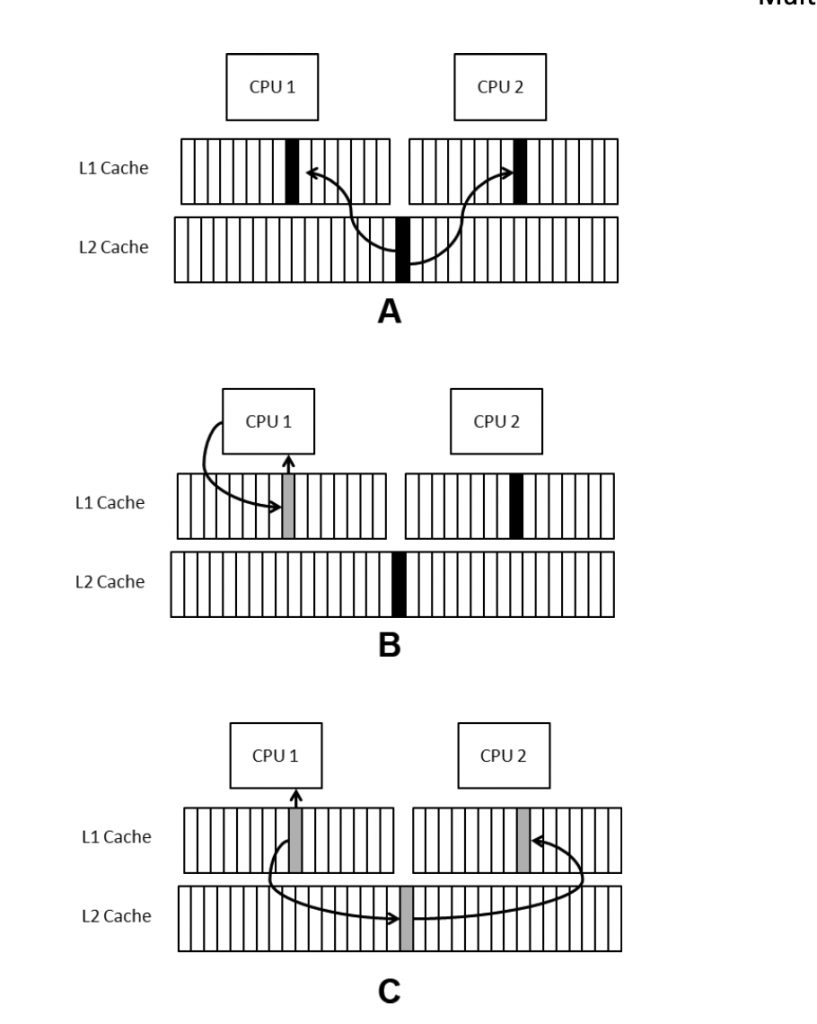
避免多个线程在同一条cacheline上频繁更新值。
使用pad来避免在同一个cacheline。
死锁
平衡
资源竞态是一个问题,但是有机会从设计上避免。打个比方你在IO的时候可以在每个线程上保存单独的副本来加快读取处理。
实践上的限制
隐藏的锁可能是第三方引入,导致性能问题。硬件有时候也会存在强制同步。
我们如何测量
查看同步中所消耗的时间。
查看API的调用是否比预期更耗时。
同时支持单线程和多线程模式,用于比较是否是性能有效的。有时候你的CPU跑单核更高效。查看资源利用率。
解决方案
首先从上层先利用Amdahl的法则估计可以提升的性能大概。你可能无法非常准确的估计。有时候你甚至可能会得到线性的性能提升,由于硬件对多线程的高效利用。
然后就是使用一个有多线程能力的profile来查看最大的性能损失在哪里。修复、测量、重复。
最好的策略是移除竞争,比如锁、信号量之类的。你要确定你的优化需要保证应用的正确性。
有一些新的策略可以使用,比如保持线程独占资源,这样会申请很多内存,但是保证了安全性。
取决你的硬件,你也许能够调用无锁算法,这样对于你的操作来说更加高效。你要小心有部分用户的硬件没有支持这些功能。
最终,使用延迟同步,如果同步很消耗,例如你可以把很多线程buffer的工作在多个元素处理完之后,合并的时候进行加锁。这样可以减少overhead。
例子
为了更好理解多线程代码,我们可以实现一些例子。
下面是读写器的例子:
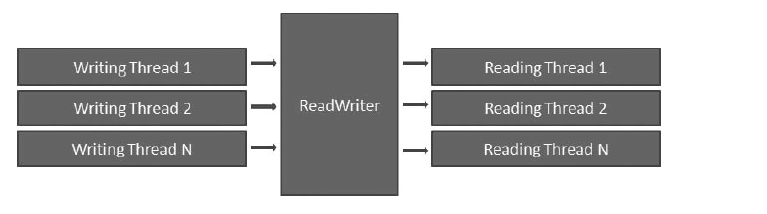
读写实现
最简单的读写器会有一些共享值,线程可以访问。写线程可以写入值,读线程可以读取。写值不保证是原子的,所以如果有一个线程正在写,那么读线程可能在未完全写入的值上读取。你必须避免这个事情的发生。
如果你保证共享值可以原子读写,也就是说共享值在Critical Section中,或者通过原子操作使用,那么整个处理会是安全的。但是这不是最优的,在最好的情况下,两个线程会线性处理,如果是反复的操作会导致,线程一直等待另一个线程离开Critical Section。
你也许会假设两个核跑50%,有一个核跑100%类似的性能,但是不是这样的。切换线程的overhead来自系统和硬件。所以两个线程轮流处理并没有一个核处理来得快。
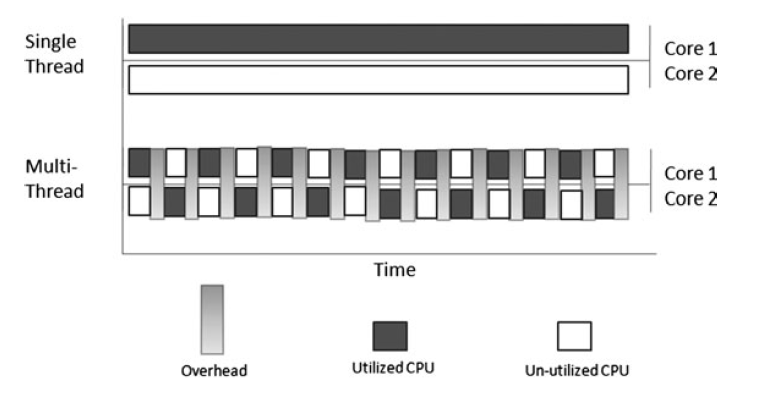
上图我们可以看到当一个核运行的时候另外核在等待,在多线程的情况下每个核花了一样的时间,但是overhead花费了大量的时间。
所以遇到竞态的时候会有大量的overhead。
数组实现
下一个优化,从一个值扩展到一个数组,类似于下图。
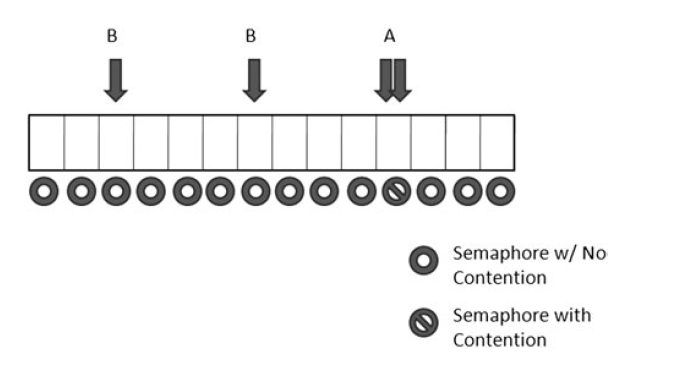
对于这个优化来说相对单个值有几个优势,竞态的情况下降了,程序还是潜在拥有竞态,你的数组大小越大,竞争的几率越小。
通过这种方式我们的利用率变得更高。
但是高的利用率不意味着更快的算法,我们要同时保证高利用率和处理效率,这就是下一个优化。
数组合批
对于我们最终的实现,我们会降低CriticalSection的数量通过对每一块数组管理一个mutex。如下图:
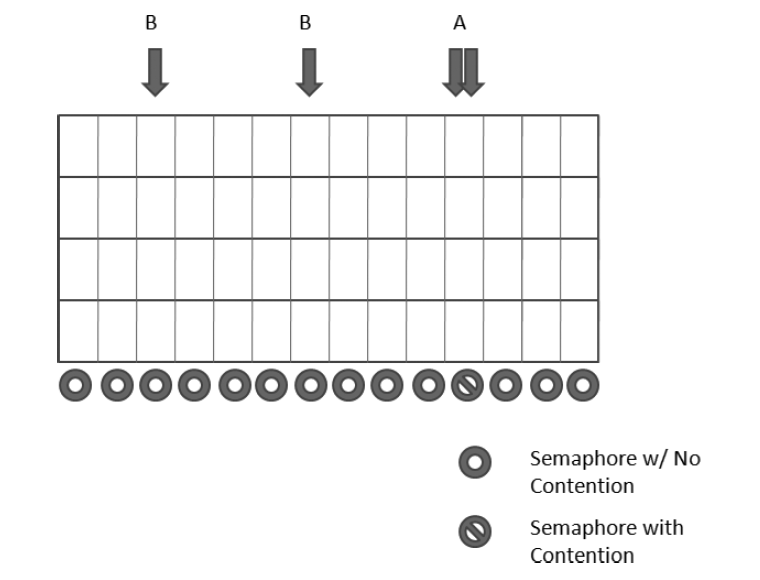
在数组实现里面,我们对每一个读写都包含了进入退出调用。而通过数组的数组我们可以对每一行进行加锁降低进入退出的overhead,使用更多的处理器来处理数据。利用率很高,而且现在处理任务更加高效,由于线性内存的原因。我们的实现性能进一步提升。
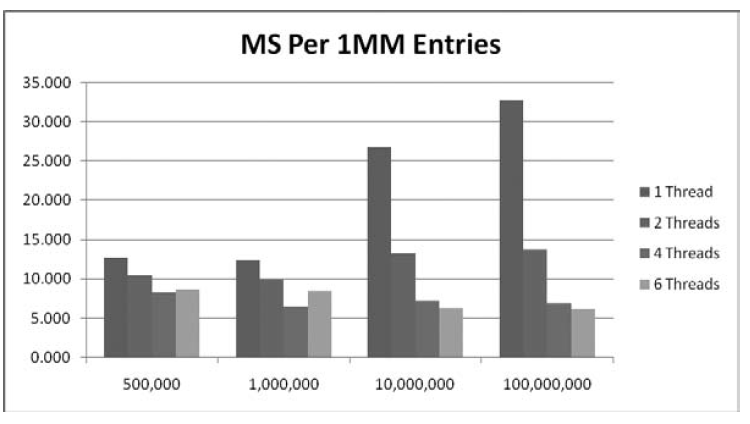
在书中的例子中,单线程的处理是11.5ms,在进行高效实现之后,4线程可以达到6.9ms。
线程数量
线程数量增加到6个时性能降低到9.1ms。当执行比核心数更多的线程时会导致过载。
最大的问题不是有过多线程,主要问题在同步,在4核上有4个线程可以并行处理,剩下两个则需要线程上下文切换。这些串行处理会导致线程运行过慢。
如果说串行是问题,那么大规模的并行算法应该问题更少。数据如下:
共享、平衡以及同步
源码中有很多代码使用了**_ _declspec(align(64))** 指导预处理器。这样做可以防止伪共享问题,消除相关问题可能发生的情况。
为了测试平衡,尝试使用不平衡的数量的reader和writer。默认情况下,对于每个writer分配一个reader。
最后,在高性能同步组件,事件提供了一个线程到另一个线程的快速信号。使用这种算法,事件比空旋加布尔要更加高效。