

在优化计算之前需要确定计算才是CPU的瓶颈。
微观优化
现在编译器上有大量的优化选项
VS中有fast floating-point模式会不那么精确但是速度会更快。
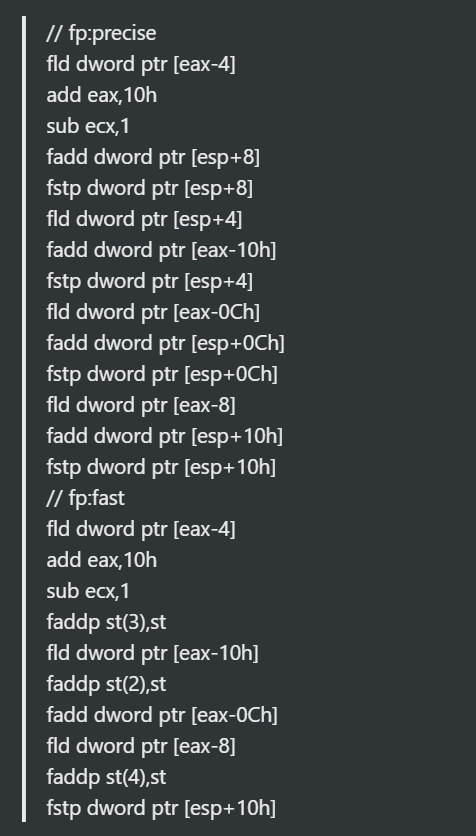
精确模式少了很多次stores/loads操作
运算Bound
在做运算Bound之前需要先确定Bound是否确实是Bound
下面介绍一些计算技巧:
查找表
例如sin和cos之类的计算可以放在查找表中,但是查找表的问题是在查找的时候将大量的数据带入到内存中,大大提高了cache missing的可能性,导致了随机访问。
所以最好的查找表要保持在比较小的尺寸,然后保持在缓存中。在不同的硬件设备中这个尺寸也有差别。
Memoization
Memoization简单的说就是将中间结果缓存,复用中间的计算结果。
最常见的地方有斐波那契数列:
F(0) = 0
F(1) = 1
F(n) = F(n1) + F(n2)
// 代码如下
int fibonacci(int n)
{
if(n==0) return 0;
if(n==1) return 1;
return fib(n1) fib(n2 );
}
我们可以使用一个Map对中间结果缓存:
map<int, int> fibonacciMemos();
int initialize()
{
fibonacciMemos[0] = 0;
fibonacciMemos [1] = 1;
}
int fibonacci(int n)
{
// Check for a memo about this number.
map<int,int>::iterator i = fibonacciMemos.find(n);
if(i == fibonacciMemos.end())
{
// Calculate the fibonacci number as we would normally.
int result = fib(n1) + fib(n2);
// Store the result for future use.
fibonacciMemos[n] = result;
// And return.
return result;
}
// Look it up and return.
return fibonacciMemos[n];
}
性能收益需要看获取内存和计算时间的差异。如果查找内存的方式是缓存友好的,那么基本上都能从中收益。
另外一个就是将memo保持在一个比较小的范围,这样可以保证缓存友好性。
如果量比较大的话也可以拆分key,也可以看情况合并key。
内联函数
大部分函数都可以依赖编译器进行内联。
减少了函数调用的消耗,但是带来的是二进制体积变大指令缓存可以缓存的东西也就越少。
一般通过你inline提示编译器。编译器通过cost/benifit分析来决定是否需要内联。
运行时才能确定执行的函数无法内联,比如虚函数或者lambda。
通过__forceinline可以强制内联,但是不推荐。
分支预测
乱序执行可以让你指令并行执行,但是分支影响了并行执行。
分支分成两种:有条件和无条件的
如果无条件那么直接跳转到相同的指令。而条件分支则会有问题,分支在指令执行完之前都无法执行。这个就是气泡。
为了解决这个问题分支预测就产生了。大部分情况下预测都比较好预测,但是如果是纯随机的分支那么CPU将会比较难以预测并且性能会遭到影响,有以下的方法来解决预测失败的问题:
让分支更可预测
if( condition[j]>50 )
sum+=1;
else
sum+=2;
例如上面的例子:如果数组中初始化如下
myArray[i]=rand()%100;
然后我们换一种方式初始化
myArray[i]=rand()%10;
下面的值均小于50,可以看到速度大概快了3.29倍
移除分支
在一些情况下你可以避免分支。你可以将一些分支操作转换为传统的计算操作如下:
if(a) z = c; else z=d;
//变为
z = a*c + (1 - a)*d;
你会发现这个操作是两倍的计算消耗,但是有效地避免了分支的出现。
Profile-Guided Optimization
一些编译器上的PGO的选项可以打开,整体地提升程序效率,但是这个并解决不了瓶颈。
循环展开
循环展开有时候可以带来更好的性能,但是如果是简单的展开:
int sum = 0;
for( int i=0;i<16;i++ )
{
sum +=intArray[i];
}
// 变为
int sum=0;
for( int i=0;i<16;i+=4 )
{
sum+=myArray[i];
sum+=myArray[i+1];
sum+=myArray[i+2];
sum+=myArray[i+3];
}
上面的例子并不会让你的速度变得更快。
编译后的结果如下所示:
两个结果一样
但是如果按照如下所示展开:
int sum=0,sum1=0,sum2=0,sum3=0;
for( int i=0;i<16;i+=4 )
{
sum+=myArray[i];
sum1+=myArray[i+1];
sum2+=myArray[i+2];
sum3+=myArray[i+3];
}
sum =sum+sum1+sum2+sum3;
下面的图可以看到性能差异
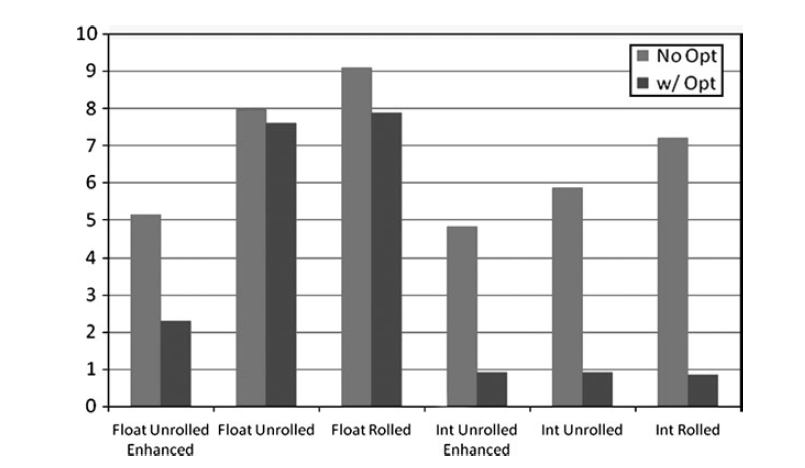
Float在循环Unroll之后收益最大。Int则收获更小,因为编译器优化已经做得足够好。
(在最新的编译器上可以尝试一下float变化会不会也因为编译器的改进而变小)
浮点数学
浮点数计算总体来说还是比较慢的。你可以通过VS的fp选项降低精度来获取更高的性能。
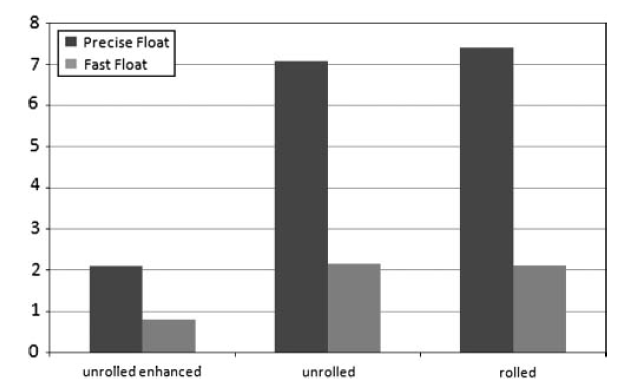
缓慢的指令
影响CPU指令性能的两个要素:延迟和吞吐量
延迟是每个指令任务的clock tick数,吞吐量总是等于或小于延迟。
延迟的例子:举个例子乘在奔腾M的吞吐量是2,浮点乘是5,除是18.
吞吐量的例子:乘的吞吐量是2也就是2个时钟周期后另外的乘可以执行。
大部分情况下编译器比你更了解CPU,会自动进行乱序处理。除了特定的瓶颈,否则都不应该自己去看这个指令优化。即使你自己内联了汇编,编译器还是大部分时候比你性能好。
优化汇编 之前,确认以下这些事情:
- 是否选择了正确的算法
- cache missing是否是瓶颈。cache line fetch比缓慢指令更加昂贵
- 编译器是否设置正确,如果设置错误,你的优化将是无意义的。
平方根
平方根很消耗运算量。大部分时候会用在距离计算上面。
可以尝试只使用距离平方来判断距离
另外一种方法是使用近似开方
float InvSqrt (float x){
float xhalf = 0.5f*x;
int i = *(int*)&x;
i = 0x5f3759df (i>>1);
x = *(float*)&i;
x = x*(1.5f xhalf*x*x);
return x;
}
位操作
各种Bit的操作
例如:
int rounded = (inNumber/4)*4;
// 替换成
int rounded = inNumber & ~3;
类型转换
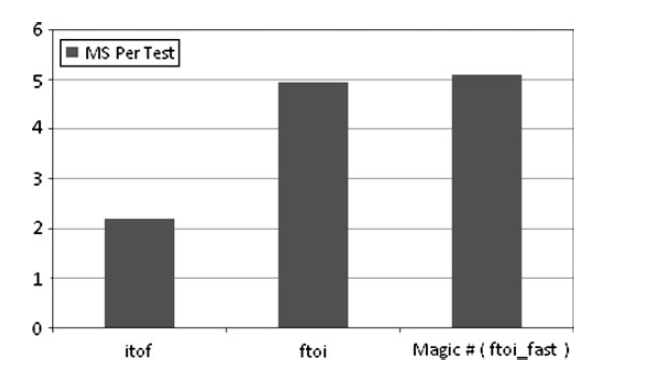
int转float很快但是float转int涉及切断会更慢。
VS有一个ftoi_fast的函数和SSE的ftoi差不多性能。
SSE指令
Vector指令在高性能领域有卓越的历史。SSE的使用和硬件的SIMD有关系。
如果想充分利用SIMD,使用已经实现了SSE支持的数学库是最快的。如果重写的你的数学库并不是最好的方式。
历史
基础
你可以通过汇编来使用SSE,但是大部分时候你会使用编译器的内置函数来处理SSE。
最方便的方式是使用已经集成了SSE的库。有一些编译器可以自动把你的代码转换成SSE指令,也叫自动向量化。
数据对齐对于SSE指令来说非常重要,方则可能会有crash。特殊的申请函数可以帮助保证对齐但是很多开发者还是会自己进行实现。
例子:添加SIMD
使用SOA的结构会更有利于并行计算
_align16_ struct Particle
{
float posX[100];
float posY[100];
float posZ[100];
float posW[100];
float velX[100];
float velY[100];
float velZ[100];
float velW[100];
}
for( int i=0;i<m_NumParticles/4;i+=4 )
{
pParticle* pPart = particleArray[i];
pPart->position += pPart->velocity;
__m128 posXvec = _mm_load_ps( pPart->posX[i] );
__m128 posYvec = _mm_load_ps( pPart->posY[i] );
__m128 posZvec = _mm_load_ps( pPart->posZ[i] );
__m128 posWvec = _mm_load_ps( pPart->posW[i] );
__m128 velXvec = _mm_load_ps( pPart->velX[i] );
__m128 velYvec = _mm_load_ps( pPart->velY[i] );
__m128 velZvec = _mm_load_ps( pPart->velZ[i] );
__m128 velWvec = _mm_load_ps( pPart->velW[i] );
posXvec = _mm_add_ps( posXvec, vecXvec );
posYvec = _mm_add_ps( posYvec, vecYvec );
posZvec = _mm_add_ps( posZvec, vecZvec );
posWvec = _mm_add_ps( posWvec, vecWvec );
//remainder of particle update
}
如果更加重度的话一般会把例子系统放到GPU上去做。
信任编译器
编译器很聪明,但是完全依赖他们去做你想做的事情,但是总来说编译器做得很好。作为开发者你没有这么多时间可以去进行底层优化,但是编译器可以。
但是在测试的时候你需要确定不能被编译器的优化所干扰。我们很难去写一个很耗的代码,大部分时候编译器会移除那些我们本来用于做baseline的代码。
了解编译器会有想不到的效果。
移除不变的Loop代码
int j=0;
int k=0;
for( int i=0;i<100;i++ )
{
j=10;
k += j;
}
上面的代码等价于
k = 1000.0f;
合并冗余的代码
void test()
{
gCommon +=TestLoopOne();
gCommon +=TestLoopTwo();
}
float TestLoopOne()
{
float test1=0.0f;
for( int i=0;i<1000;i++ )
{
test1 += betterRandf();
}
return test1;
}
float TestLoopTwo()
{
float test2=0.0f;
for( int i=0;i<1000;i++ )
{
test2 += betterRandf();
166 Chapter 7 n CPU Bound: Compute
}
return test2;
}
LoopOne和LoopTwo是一样的函数,主要用于移除模板产生的冗余代码。
循环展开
编译器会自动帮我们的循环进行展开。但是如果其中设计到全局变量,编译器不会进行完全优化,因为中间的值可能会发生改变。
跨Obj优化
编译器现在可以跨编译器优化,称为全程序优化。
特定硬件优化
一些编译器提供了特定硬件选项,对于PC开发者而言,有上千的选项需要处理,而主机平台而言则有更大的意义。
使用CPUID等方法来获取PC的信息。使用这个信息来进行机器分级,了解处理器、cache尺寸或者指令集是否支持。
对于一些渲染设置则有些可以给玩家自行设置。
结论
这章提供了查找表、内联、分支预测、避免慢指令、使用SIMD指令式来加强你的性能。
还是要记住,计算力进步远快于内存获取的速度。