

计算机通过时间和空间运行,指令代表时间、内存代表内存。
检测内存问题
内存获取问题大部分情况下都不可见。除非你查看汇编代码。
你可能获取的是寄存器、堆、栈、或者内存空间映射到另外一个bus。
数据有可能缓存在L1、L2、或者L3,有可能对齐也可能没有。
二分查找一般来说比线性查找要快,但是因为随机获取内存,所以在小的搜索上效率还不如线性查找。所以数据量的大小也决定了你的trade-off。
使用工具查看内存阻塞和cache miss
如果没有工具的话可以通过时间测量来猜测和检查具体的瓶颈点。举个例子,在循环当中只对数组的第一个进行操作,来确定是否有cache missing的影响。
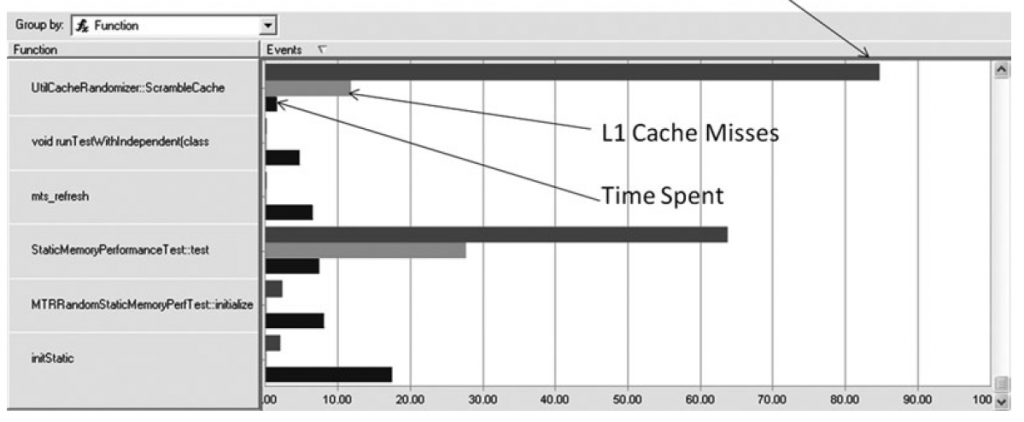
解决方案
由于物理限制,制造商只能通过cache和预测技术来隐藏延迟,例如pre-fetch。
用于优化内存使用来影响cache的技术:
- 降低运行时和编译时内存的footprint
- 使用memory移动、fetch较少的算法
- 通过物理局部化、适当的布局和正确的对齐
- 增加时间连贯性
- 利用pre-fetch
- 避免糟糕的获取模式来打破cache
其中降低内存footprint和增大cache是一样的,减少cache不够用的情况。
减少memory移动和fetch对于应用优化来说也非常重要。这里在算法选择上进行trade off,是否需要选择效率更高但是memory fetch更频繁的算法。
Pre-Fetching
CPU会识别内存获取的模式提前将memory获取,来隐藏延迟。
大部分情况下硬件pre-fetching优于软件pre-fetching
在使用软件prefetching的时候要特别注意测试是否性能有提升,否则pre-fetch反而会是一种浪费。
如果你遇到cpu没有支持硬件pre-fetch或者一些极少数的情况下软件prefetch确实有很大作用。
访问模式和缓存
4种访问模式
- 向前线性访问 linear access forward
for(int i = 0; i < numData; i ++) {
memArray[i];
}
- 向后线性访问 linear access backward
for(int i = numData-1; i >= 0; i --) {
memArray[i];
}
- 周期性访问 periodic access
使用一般的布局来访问struct随机变量
struct vertex
{
float m_Pos[3];
float m_Norm[3];
float m_TexCoords[2];
};
for(int i = -; i < numData; i ++)
}
vertexArray[i].m_Pos;
}
- 随机访问 rendom access
float gSum = 0;
void Test()
{
for(int i = 0; i < numData; i ++)
{
gSum += vertexArray[RandI()];
}
他们的性能对比下来是这样的:
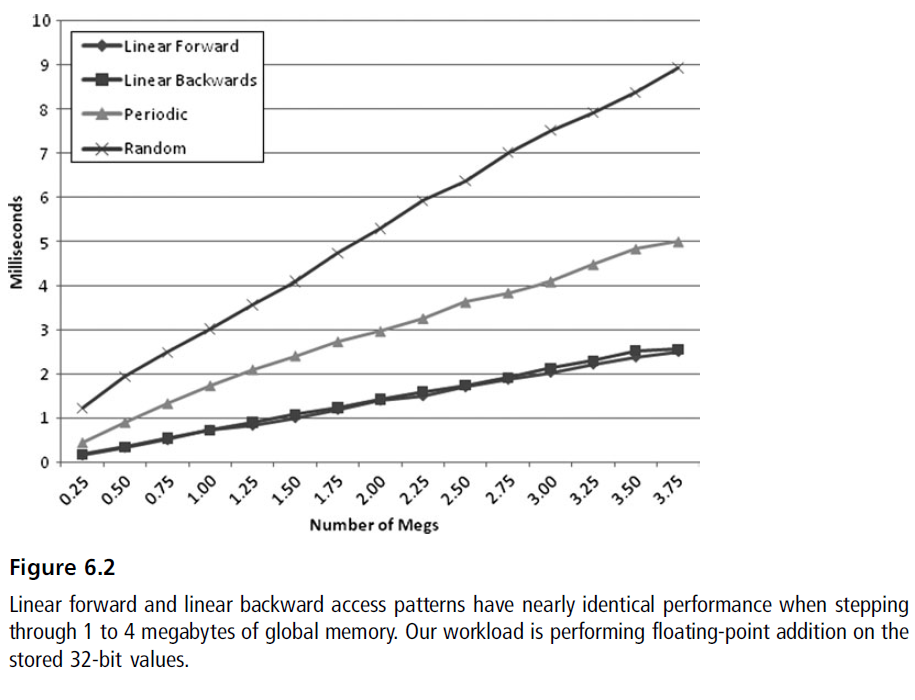
- 随机访问效率是最糟糕的
- 周期性访问在线性访问和随机访问之间,具体取决于布局的大小。情况最糟糕的时候周期性访问可能慢于随机访问。
- 线性访问则是最快的
申请大内存块对于线性移动来说很快,但是是有意义的,图形API对这个非常擅长。但是很难对所有的解决方案都使用大数组。申请和释放大数组是很消耗的,而且很多时候你需要对数组进行顺序转换。必须在实现中进行权衡。
以一种方法在固定申请和动态申请之间。其实就是使用Block,然后在数组变化的时候追加新的Block。
对于大块数据处理因为线性获取的好处性能有提升,但是也是需要权衡的。一些情况下线性访问并不是最好的。
随机访问可以显著降低你的性能。一个树状结构可以很容易地让你的性能下降。
在每个item上进行大量操作的时候你可以通过pre-fetch来隐藏乱序访问的消耗。当然你还是要自行考虑你的访问模式。
CPU做了大量的memory的工作,内存系统可以按照预期地fetch内存。当你线性向前或向后访问的时候硬件的prefetch可以最大程度高效地使用缓存工作。
随机性
随机性是否总是会导致更慢,这个主要取决于问题的尺寸。
如果你处理小尺寸的struct然后获取成员,你可能察觉不到区别。如果struct可以装进cacheline而且是对齐耳朵,那顺序不会有任何的性能影响。
如果是大的struct则影响会变大。
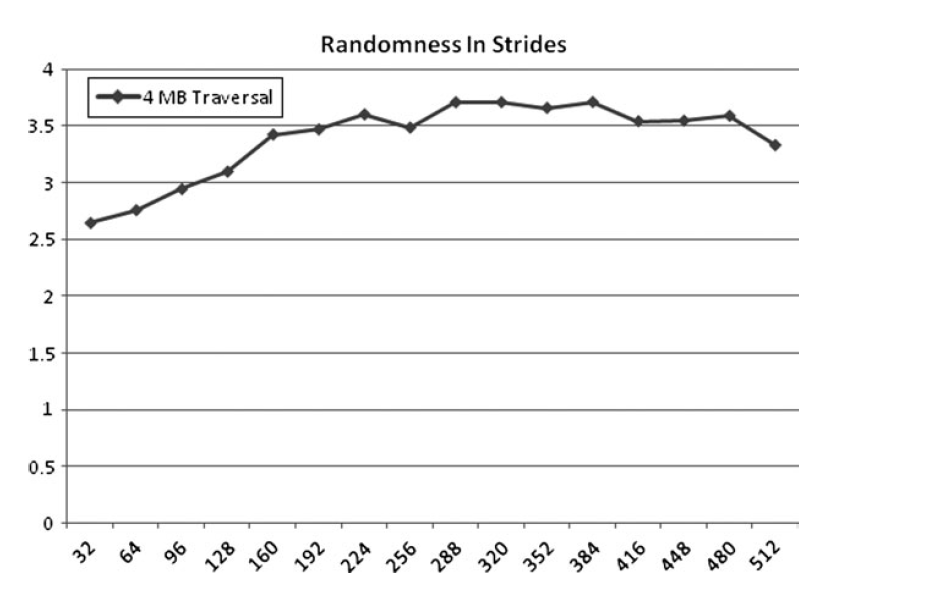
流
目前只讨论了单个内存流。大部分CPU可以支持多条内存流。
高效的流数量很难概括,和处理器、芯片、操作系统等都有关系。
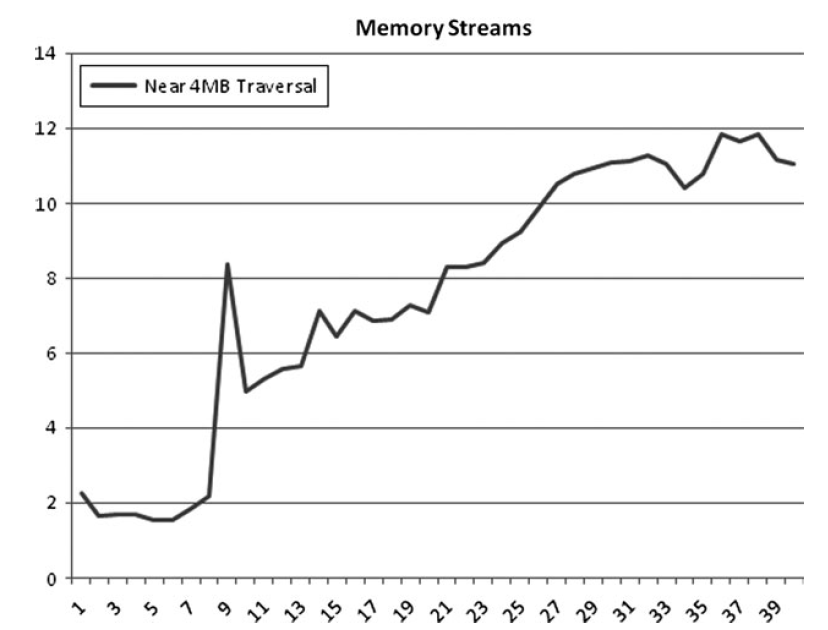
最好的方法是测量,从8到16条流之间。你内存获取的大小在稍微小于4M的地方、也就是稍微小于系统的内存页。
4核 3Ghs的Intel Xeon的CPU测试的时候8条流是性能最高的,之后性能会变得更糟糕。
在不同设备上需要自行测试。
AOS 和 SOA
内存布局是很关键的,一般有两种主要的方式:
array of structures (AOS).
接近线性访问
struct aos
{
float m_Float1;
float m_Float2;
float m_Float3;
float m_Float4;
};
aos myArray[256];
structure of arrays (SOA):
更接近于周期访问
struct soa
{
float m_Float1[256];
float m_Float2[256];
float m_Float3[256];
float m_Float4[256];
};
soa myArray;
了解AOS和SOA的方式帮助你提高多线程的性能。
解决方案:Strip Mining
通过Strip Mining你可以在遍历的时候采用分块的方式,每一块都去适应cache的大小。
保持时间连续性以及空间局部性
例如:
原本写的方式是这样的:
for( int i=0;i<numStructs:i++ )
{
m_Vertex[i].pos = processPos(&m_Vertex[i].pos);
}
for( int i=0;i<numStructs:i++ )
{
m_Vertex[i].normal = processNormal(&m_Vertex[i].normal);
}
修改之后需要按照BlockSize去进行遍历.
BlockSize需要根据不同的处理器来区分。
for( int j=0;j<numStructs;j+=blocksize)
{
for( int i=j;i< blocksize;i++ )
{
m_Vertex[i].pos = processPos(&m_Vertex[i].pos);
}
for( int i=j;i<blocksize;i++ )
{
m_Vertex[i].normal = processNormal(&m_Vertex[i].normal);
}
}
栈、全局、堆
通过new申请、添加function本地变量、添加static变量。
对于应用开发者可能没区别,但是底层实现的细微差别可以帮助优化。
栈
函数中的本地变量,因为存在栈上,空间局部性和时间连续性都很优秀。
栈空间有限,特别是递归代码,缩小栈使用可以提供更好的性能。
全局
全局内存作为你程序image的一部分被申请。是去除内存碎片的好办法。
全局内存基于连接器获取object的顺序来申请。因此,如果是申请非常频繁的对象可以选择放在同一个链接单元。
一个重要的警告:全局变量在多线程获取的时候性能会由于同步导致下降,一般称作伪共享。
堆
堆上分配,一般就是new和delete。时间久了之后会出现大量内存碎片,我们需要尽可能避免。
申请和释放内存非常消耗性能。内存管理可能会非常复杂,一般用内存池或者记录操作。有时候也会很耗。
动态内存的消耗不可避免,但是有很多策略可以避免消耗。
解决方案:不要申请
移除new操作符并且 只静态申请
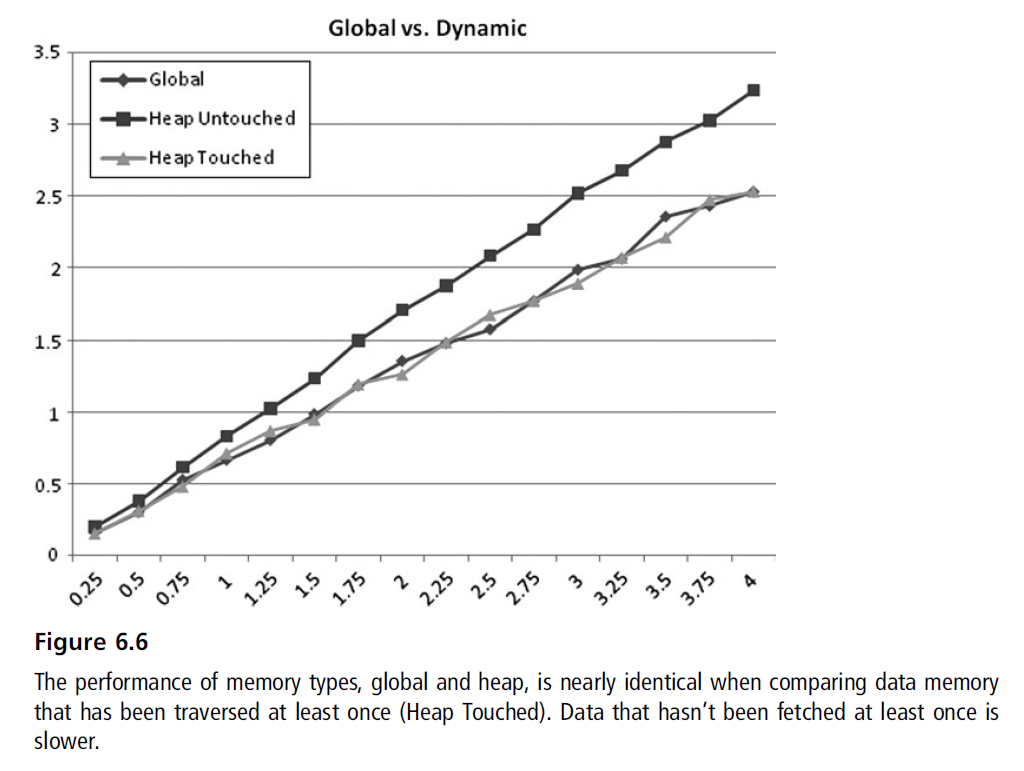
解决方案:线性申请
以粒子系统为粒子,粒子系统当中有很多小的数据结构,动态申请导致两个严重后果:
- 内存碎片化
- 导致随机访问
如果你使用线性数组来保存那么会有两个好处
- 申请活动次数降低。活动和非活动的数组分开,形成一个类似于池的结构。
- 线性的访问让你的性能变得更好
数组大小变化很快的时候可能工作没这么好,比如爆炸的时候产生大量粒子,这个时候需要申请大量空间。爆炸结束之后粒子数量减少,多余的内存实际上是浪费的。
解决方案:内存池
内存池让你的内存哦更加连续,并且最大化性能。防止内存碎片的发生,减少内存申请导致的性能问题。
解决方案:不要构造和析构
POS 是没有构造和析构的数据结构。
当数组申请的时候构造会在每一个实例上进行。例如Mesh数据你必须等待上百万个数据初始化。
如果你避免了构造和析构你可以省很大一块时间。
解决方案:Time-Scoped Pools
定义好内存所需的范围可以在这上面下一些文章。
很多游戏实现了Level相关的池,生命周期只在当前关卡里面。这样离开关卡的时候可以直接抛弃整个池子。
另一个是基于帧的申请器。不断从栈上面申请帧。比如在函数开始的时候记录stack的位置。等函数结束的时候位置网上的内存可以直接抛弃,重置成0。不过这种申请方案可能有数据对齐的问题。
运行时性能
下面是一些实现上的经验:
别名
指针别名别名发生在两个指向同一个地址的指针。
有别名:
void foo(int *array,int *size,int *value) {
for(int i=0;i<*size;++i) {
array[i] = 2 * *value;
}
}
无别名:
void foo(int *array,int size,int value) {
for(int i=0;i<size;++i) {
array[i] = 2 * value;
}
}
stackoverflow上有这么一个回答:
https://stackoverflow.com/questions/9709261/what-is-aliasing-and-how-does-it-affect-performance
无别名的情况可以比有别名的情况要快30%左右。
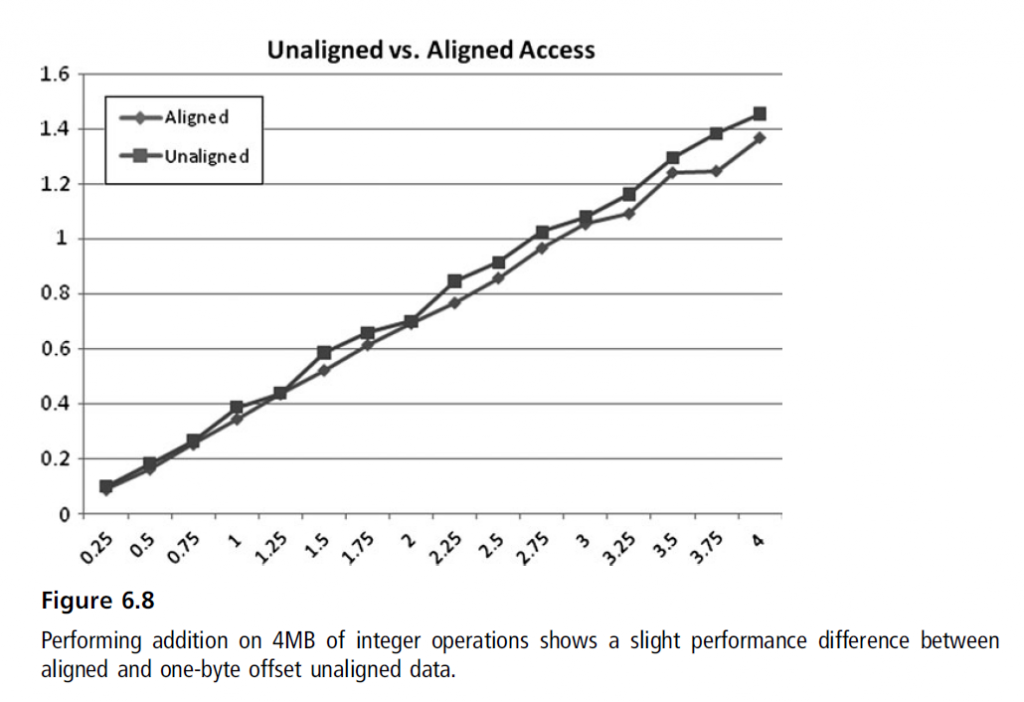
运行时内存对齐
对齐的数据和未对齐数据中有细微的差别。
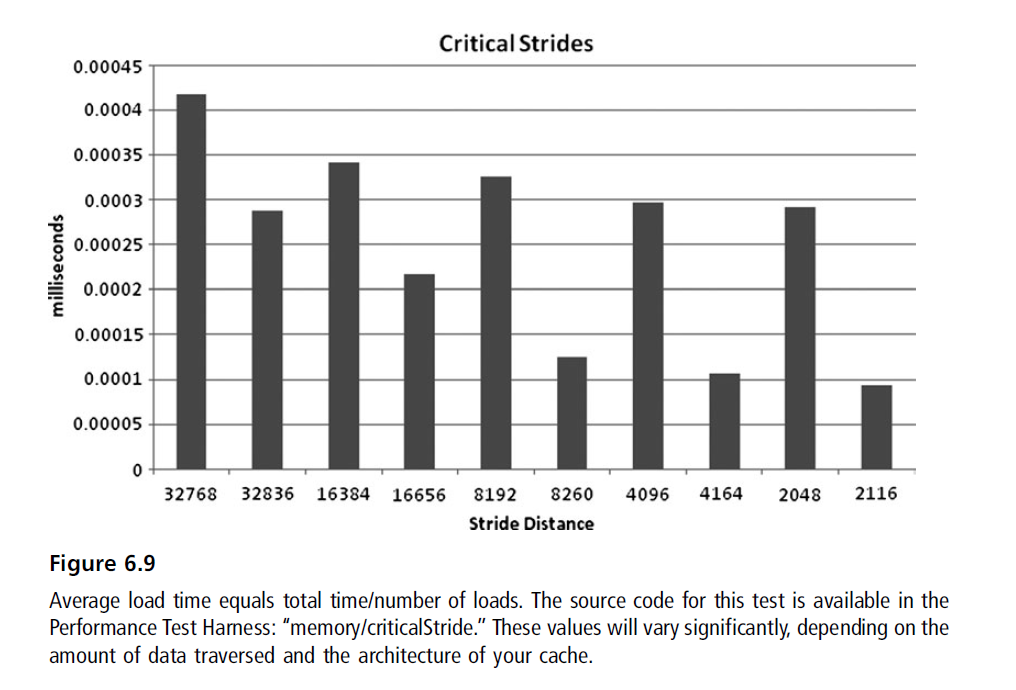
修复重点Stride问题
减少大的二次幂数组。大结构导致先前的缓存失效。
SSE加载和Pre-fetch
通过SSE可以实现SIMD等并行处理方法,工作得更快。
通过SSE还可以实现软件pre-fetching。
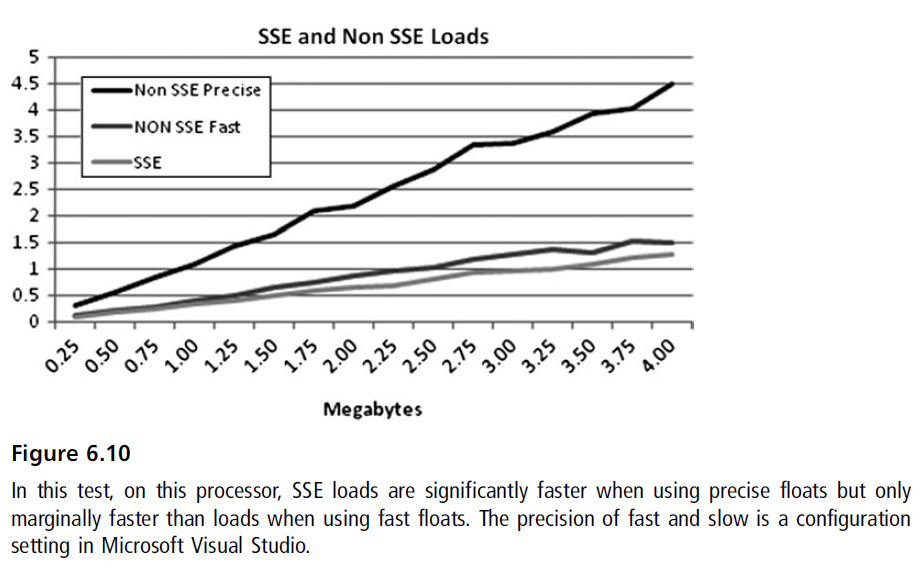
在使用软件pre-fetching的时候要特别进行测量。可以通过将获取模式改为线性来作为替代方案,来保证获取最大的硬件pre-fetch收益。
Write-Combined内存
通过Bus获取CPU内存是很大的问题。即使设备的带宽足够也是这样。例如更新vertex buffer,把数据回读会有明显的延迟。
所以Write-Combining实现了。
TODO..
总结
内存访问模式是应用程序性能中的一大块。学习trick可能会消耗大量时间,但是基础都是一样的:
- 测量很重要
- 你无法避免cache miss但是你可以降低它们
- 不同处理器的内存系统都不一样,你需要确保你用户的硬件性能
- 多做一些内存保存和线性访问的优化
最快的内存是从不申请内存。寻找缓存友好的算法。如果工作集足够小,实际上你不需要用到任何的这章提到的知识。