

以下是几条优化C++的方法
如何获取最高性能?
- 选择正确的算法
- 使用低overhead的语言(C++、Rust)
- 正确的编译选项
- 了解底层硬件
了解底层硬件可以帮助我们获取更多的性能
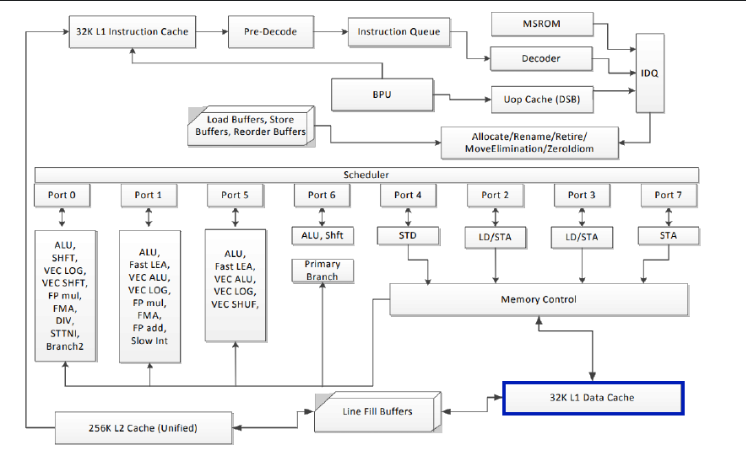
仅仅通过C++代码是无法预测性能的,性能很依赖CPU与内存的底层实现。

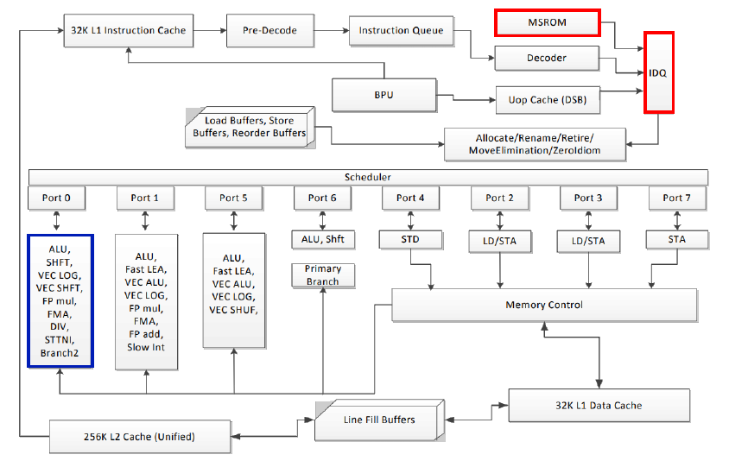
上图为Intel大概的构架。
分支预测
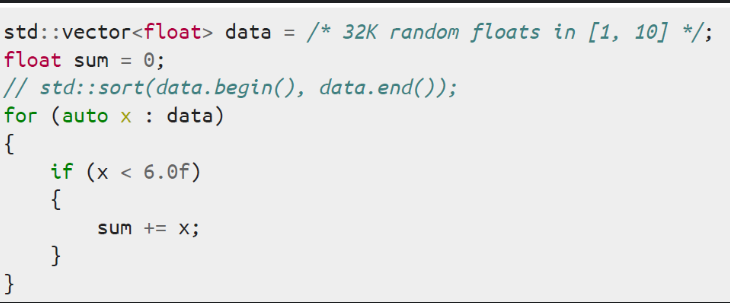
数组排序与不排序,性能会差一倍

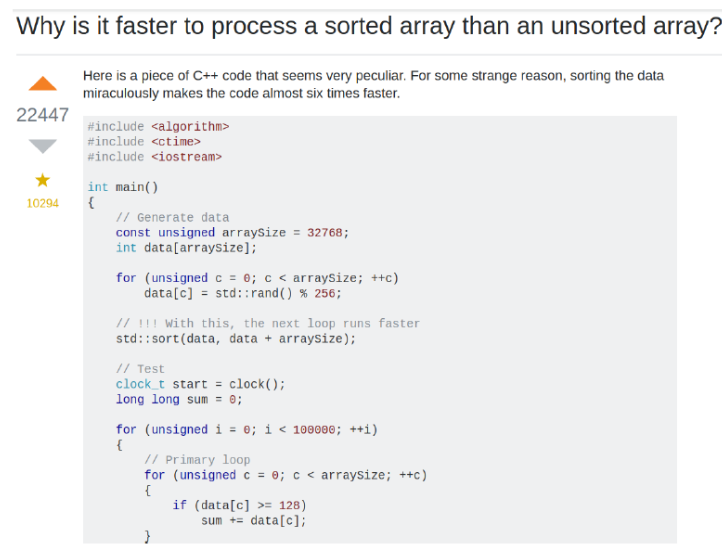
通过Vtune可以看到相关耗时
其耗时来自预测。

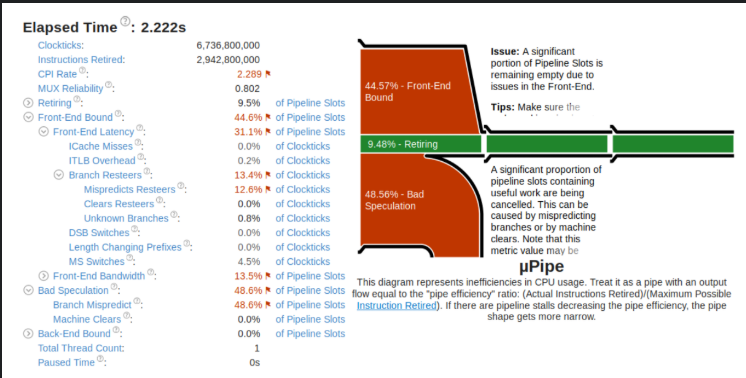
构架中的BPU用于分支预测,分支预测失败越多耗时就越长。
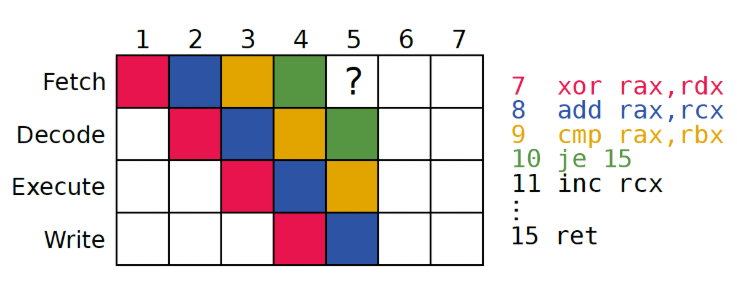
在第五个时间戳的时候cpu并不知道要执行啥,所以会进行分支预测,继续执行。
如果预测失败可能会导致15~20个cycle


编译器也会做相应优化,如果数字为int时编译器会自动去除分支。



除了分支以外,以下这几项也会导致分支预测:
- 函数指针
- 函数返回地址
- 虚函数
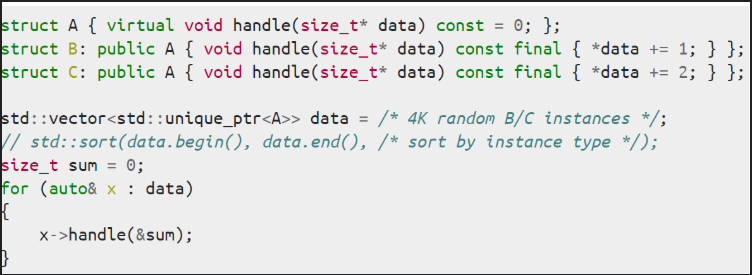
以下代码,如果同一种同时执行效率更高。

命中缓存

int的vector,vector的offset不同。
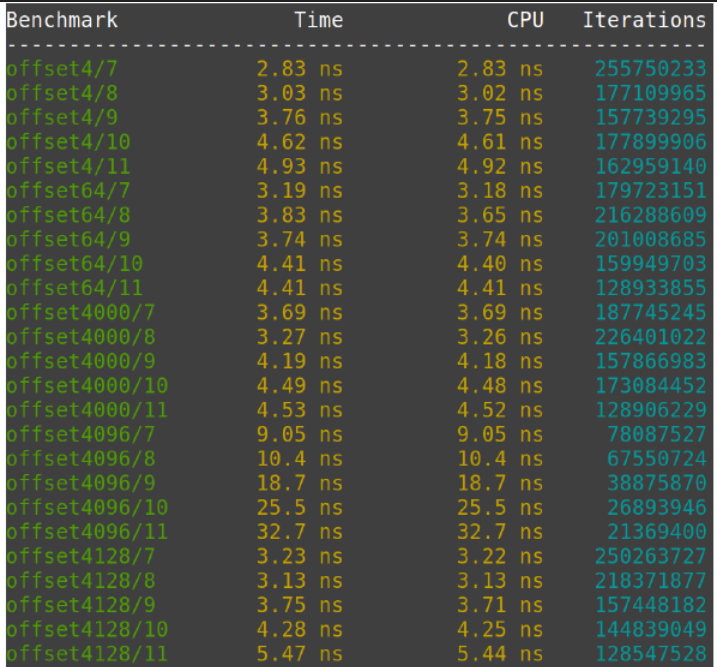
发现Offset不同的情况下性能也不一样。
这个性能的差异是L1 Data Cache引起的。
L1的实现是通过硬件实现的hashtable实现的 Key占8字节,cacheline占64字节
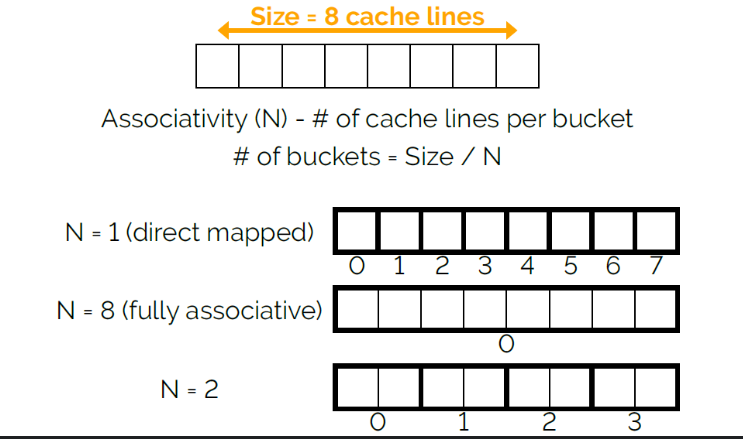

我们可以通过l1d.replacement看到cache missing的次数

数值计算
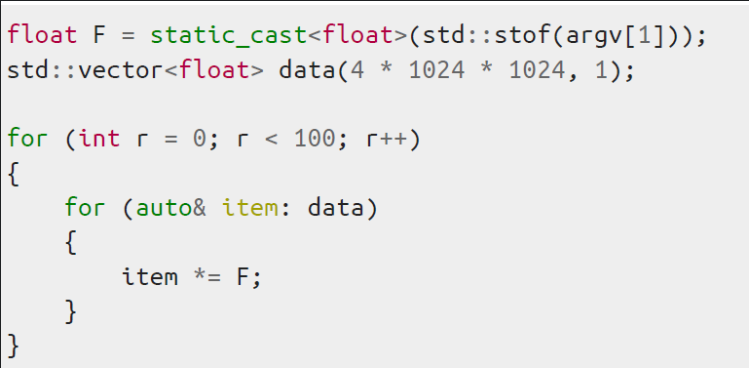
上述代码,不同的数字计算的速度并不一样。

为整数时计算比0.3等特殊数字要快得多,值得注意的是0.5也很快(二次幂)。

这个实际上和硬件相关的处理模块也有关

通过fp_assist.any可以看到浮点计算的开关次数

在Intel的芯片上可以用相应的开关加速计算

多线程访问

同时访问同一块内存,线程越多,速度越慢
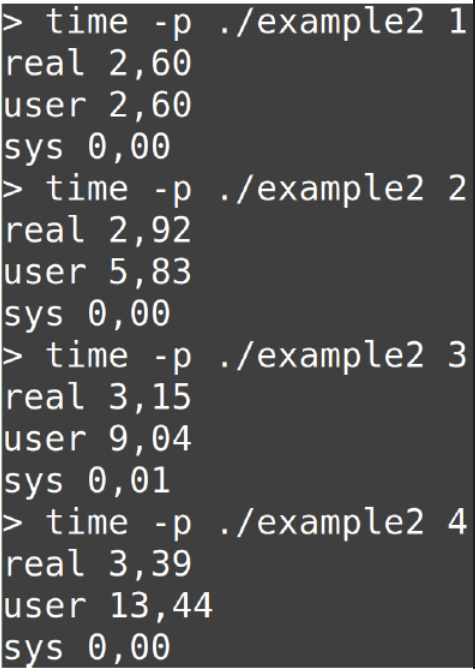

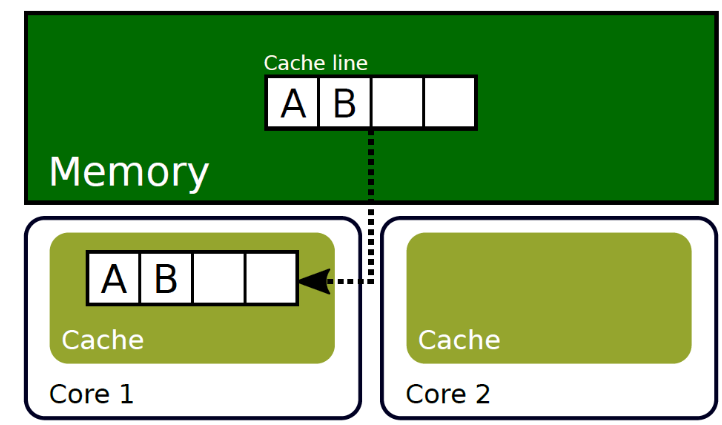
第一个核读入了A,
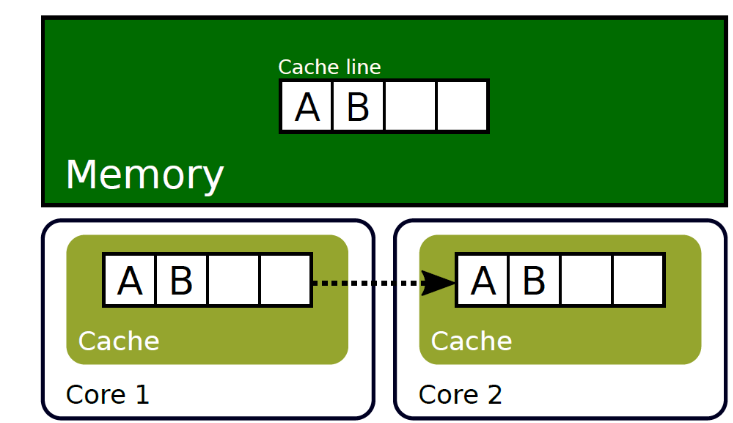
第二个核读取的时候,会从第一个核中读入,会比从内存中读取更多

第二个核写入的时候第二个核的数据和第一个核不同步了。
导致需要将数据同步到第一个核
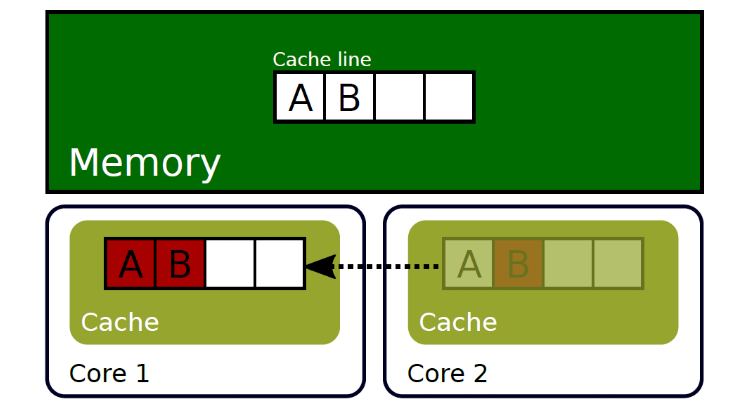
为了解决这个问题,我们可以将不同的操作数放到不同的cacheline中。
例如原来的cache分布是这样子:
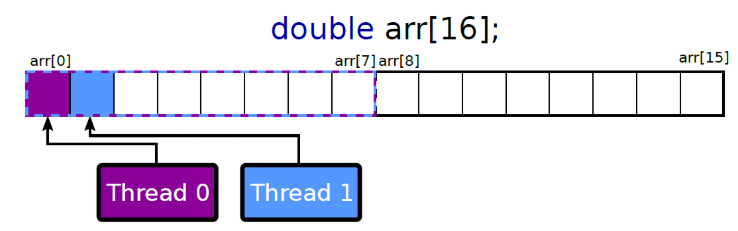
我们可以将数字放到不同的cacheline中,
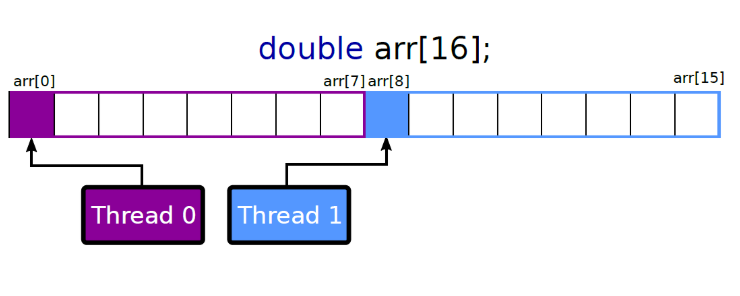
这样就不会产生写入的冲突。

用这个命令可以看到不同核数据失效的次数
源码
